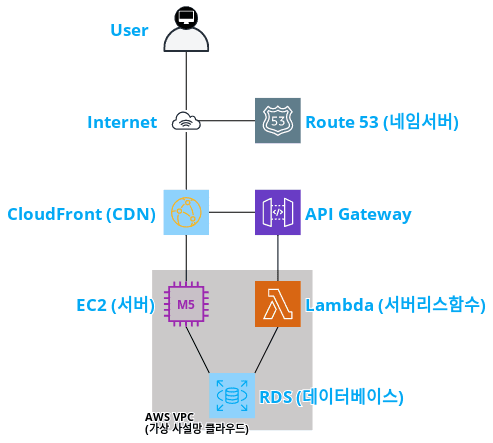
AWS SES (Simple Email Service) 는 직접 구축이 어려운 이메일 서비스를 제공한다.
sendmail 으로 SMTP 구성을 사용할 수 있지만 보통 스팸 방지를 위한 여러 솔루션에 의해서 차단이 되기 때문에
직접 sendmail 서비스를 구성하고 서비스 하기 위해서는 광범위한 공부가 필요 하다.
1. sendmail – smtp 구축
2. KISARBL 등록 (이것은 한국의 포털 쪽으로 메일 서비스 원활히 발송하기 위해 필요 하다.)
3. ReverseDNS 등록 (이건 해외 포털 서비스 쪽과 관련이 있다. Internet Service Provider 에서 등록이 가능하다. – KT, SK, U+ 등등..)
4. DKIM, DMARC 설정 (해외 포탈 gmail, yahoo 등등)
아울어서 주기적인 IP 신뢰도 관리를 위해 서버내에서 발송되는 메일을 추적, 통제 해야 한다.
AWS SES 는 월 62,000건 까지는 무료로 발송이 되며 이후 초과 되는 1000개의 메일당 약 100~150원 정도의 비용이 발생 한다.
물론 수신자의 스팸 신고가 많거나(1%) 허위 메일 주소로 발송(5%)되면 메일 발송 서비스가 차단 된다.
메일 발송을 위한 SMTP 계정은 생성을 하게 되면 auth 계정이 할당 되게 되며 사전에 등록된 메일 주소로만 발송을 할 수 있다.
문제는 ID / PW 형식 이기 때문에 유출 되었거나.. 혹은 패스워드 생성일이 오래 되면 보안상 바꾸어 주어야 한다.
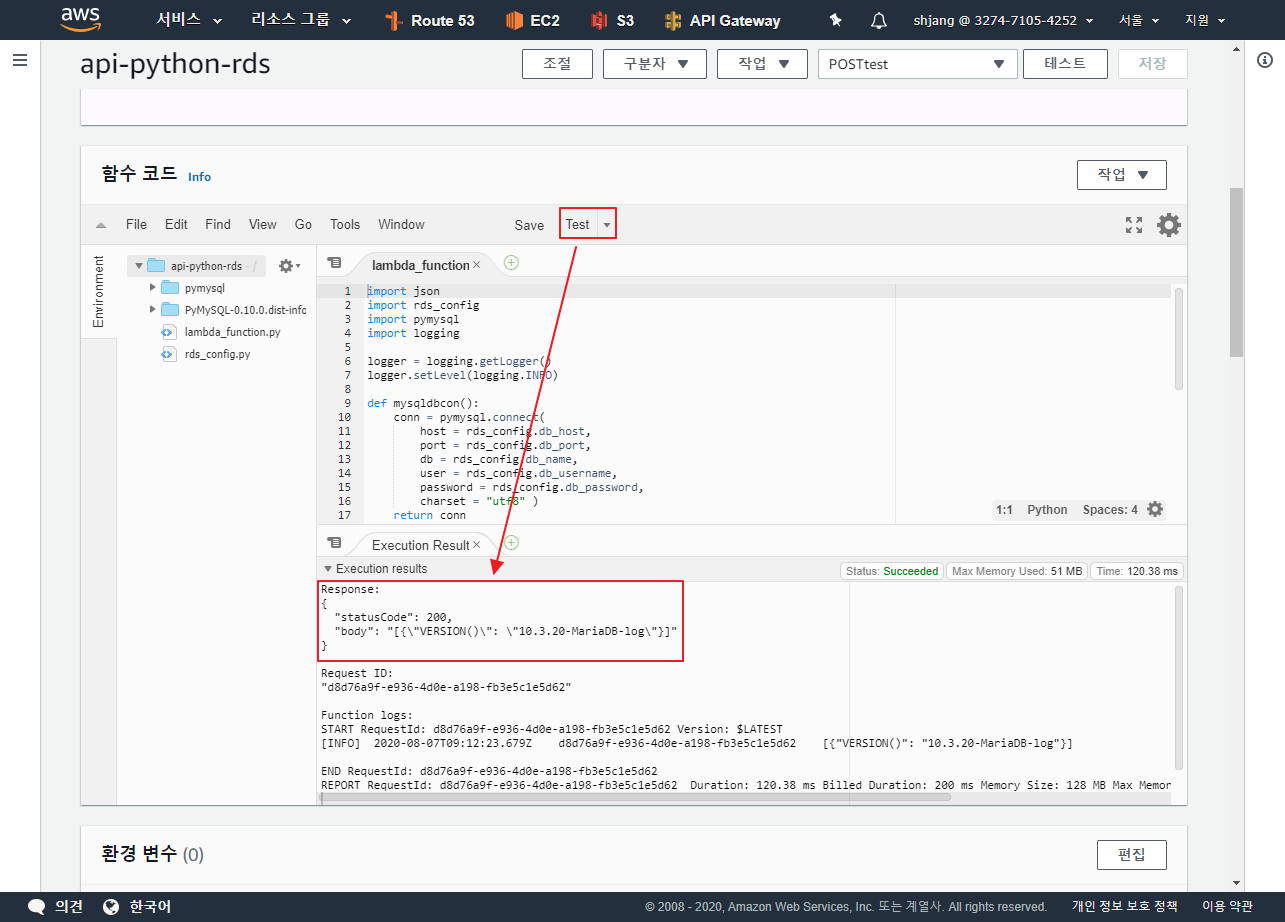
AWS – IAM 에서 일반적으로 생성하는 액세스 키는 20글자 시크릿 키는 40 글자 를 차지 한다.
AWS – SES 에서는 SMTP 계정을 만들때 패스워드 길이가 44 글자를 가진다.
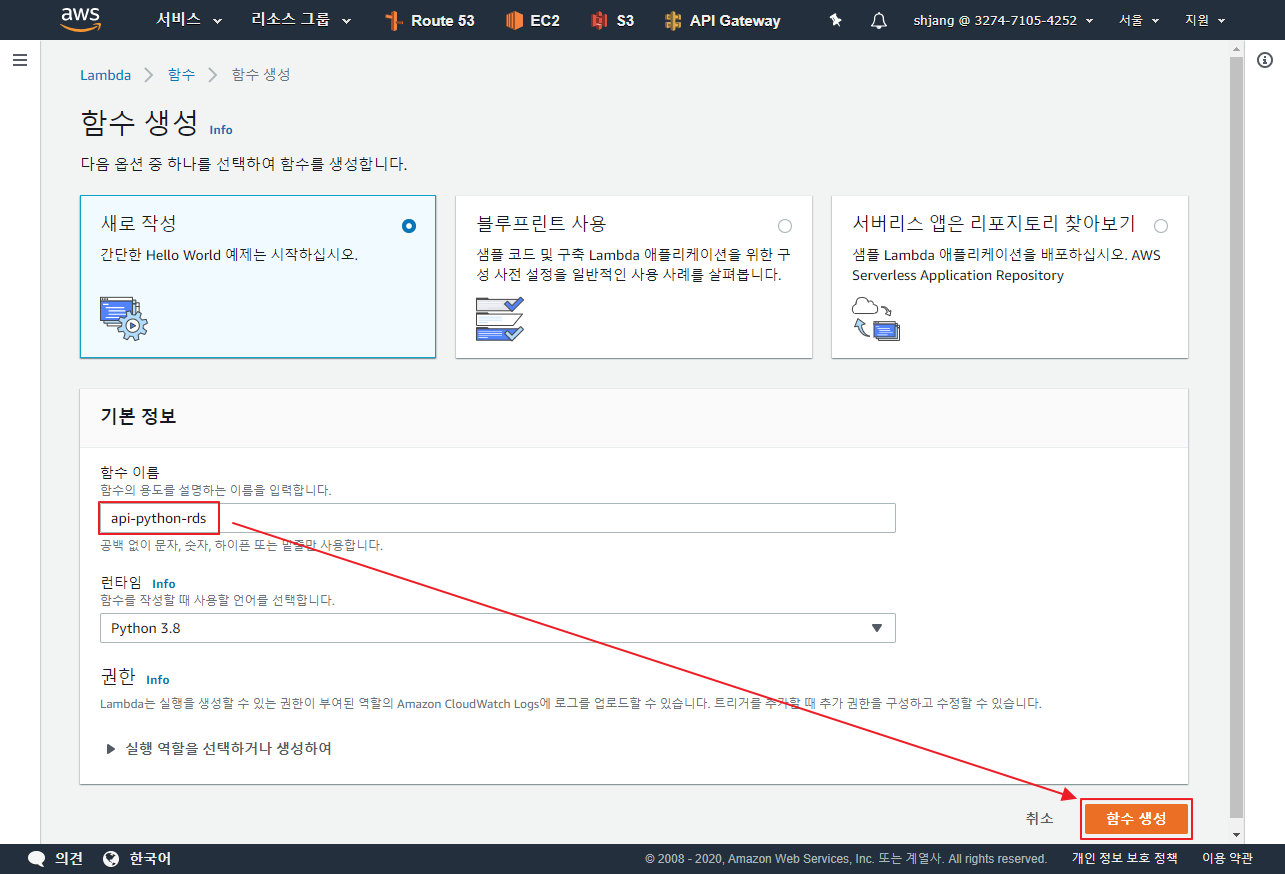
즉 SES 메뉴에서 “Create My SMTP Credentials” 생성한 계정을 사용할 수 있다.
그래서 찾아 보니 아래와 같은 메뉴얼을 찾을 수 있었다.
https://aws.amazon.com/ko/premiumsupport/knowledge-center/ses-rotate-smtp-access-keys/
근데 이해는 잘 되지 않는…
종합해보면 기본으로 제공 되는 파이선코드 를 이용하여 컨버팅 해서 써야 한다는 말이다.
시스템 엔지니어링을 하는 입장에서는 생성된 값을 테스트 하고 넘겨 줘야 하는 부분도 있고 python3 전용인 부분도 조금 마음에 안들어서
패스워드 생성 후 SMTP 테스트를 진행 하도록 하였다. ‘ㅅ’a
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 |
#!/usr/bin/env python # -*- coding: utf-8 -*- import sys import hmac import hashlib import base64 import argparse import smtplib import email.utils from email.header import Header from email.mime.text import MIMEText from email.mime.multipart import MIMEMultipart def smtp_test(frommail, tomail, acckey, seckey, region): SENDERNAME = 'PySender' SENDER = frommail RECIPIENT = tomail USERNAME_SMTP = acckey PASSWORD_SMTP = seckey HOST = "email-smtp." + region + ".amazonaws.com" PORT = 587 print("SMTP: email-smtp." + region + ".amazonaws.com:"+str(PORT)) print("AUTH: ID="+acckey+" PW="+seckey) print("From: "+SENDER+" To: "+RECIPIENT) SUBJECT = 'AWS SES 메일 테스트' BODY_TEXT = """Amazon SES SMTP Email 테스트 현재 이메일은 Amazone SES 를 통해 발송 되었으며 Python 언어의 smtplib 라이브러리를 사용합니다.""" BODY_HTML = """<html> <head></head><body> <h1>Amazon SES SMTP Email 테스트</h1> <p>현재 이메일은 Amazone SES 를 통해 발송 되었으며 <a href='https://www.python.org/'>Python</a> 언어의 <a href='https://docs.python.org/3/library/smtplib.html'>smtplib</a> 라이브러리를 사용합니다. </p> </body></html>""" msg = MIMEMultipart('alternative') msg['Subject'] = Header(SUBJECT, 'utf-8') msg['From'] = email.utils.formataddr((SENDERNAME, SENDER)) msg['To'] = RECIPIENT msg.attach(MIMEText(BODY_TEXT, 'plain', 'utf-8')) msg.attach(MIMEText(BODY_HTML, 'html', 'utf-8')) try: server = smtplib.SMTP(HOST, PORT) server.ehlo() server.starttls() server.ehlo() server.login(USERNAME_SMTP, PASSWORD_SMTP) server.sendmail(SENDER, RECIPIENT, msg.as_string()) server.close() res = "Email sent!" except Exception as e: res = "Error: " + e return res def sign(key, msg): return hmac.new(key, msg.encode('utf-8'), hashlib.sha256).digest() def calculate_key(secret_access_key, region): SMTP_REGIONS = ['us-east-1', 'us-east-2', 'us-west-2', 'us-gov-west-1', 'sa-east-1', 'ap-northeast-1', 'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2', 'ap-south-1', 'ca-central-1', 'eu-central-1', 'eu-west-1', 'eu-west-2'] if region not in SMTP_REGIONS: raise ValueError("The "+region+" Region doesn't have an SMTP endpoint.") signature = sign(("AWS4" + secret_access_key).encode('utf-8'), "11111111") signature = sign(signature, region) signature = sign(signature, "ses") signature = sign(signature, "aws4_request") signature = sign(signature, "SendRawEmail") signature_and_version = bytes([0x04]) + signature if sys.version_info[0] == 2: signature_and_version = '\x04'.encode('utf-8') + signature smtp_password = base64.b64encode(signature_and_version) return smtp_password.decode('utf-8') def main(): parser = argparse.ArgumentParser(description='AWS IAM Secret Access Key to SMTP password.') parser.add_argument('AccessKEY', help='AWS IAM - Access Key ID') parser.add_argument('SecretKEY', help='AWS IAM - Secret Access Key') parser.add_argument('REGION', help='AWS SES - Region - us-west-2, ap-south-1, etc...') args = parser.parse_args() seskey = calculate_key(args.SecretKEY, args.REGION) print('make SMTP Password complet.') print('testing send e-mail? (Y/n) ') read = str(sys.stdin.readline()) if read in ('Y\n', 'y\n'): print(smtp_test("FROM@메일주소.com", "TO@메일주소.com", args.AccessKEY, seskey, args.REGION)) else: print("AWS-SES ID: " + args.AccessKEY) print("AWS-SES PW: " + seskey) if __name__ == '__main__': main() exit(0) |
사용 방법은 다음과 같다.
|
1 2 3 4 5 6 7 8 9 |
~]# ./aws-iam-secret_2_aws-ses-smtp-password.py [IAM엑세스키] [IAM시크릿키] [SES리전] ~]# ./aws-iam-secret_2_aws-ses-smtp-password.py AKIAUYPWLXWWGIYWWM4Q 3GYODowMLpLHyQxGRluCrpm0v5jatueqctIcwcGz ap-northeast-2 make SMTP Password complet. testing send e-mail? (Y/n) AWS-SES ID: AKIAUYPWLXWWGIYWWM4Q AWS-SES PW: BL9kb7yvHjw+579VGgM9I0tGYaduQO/iRITu4hzqizpm |
IAM 아무렇게나 생성된 계정에서는 작동하지 않고, 계정에 ses:SendRawEmail 권한이 부여 되어 있어야 작동 한다. (SES 에서 생성한 계정은 이미 부여가 되어 있을 것임.)
ps. 위에 예시된 엑세스키/시크릿키/SMTP비밀번호는 이 글을 포스팅 한 이후 모두 삭제 했으니까 굳이 테스트 해보지 않으셔도 된다. ‘ㅅ’a