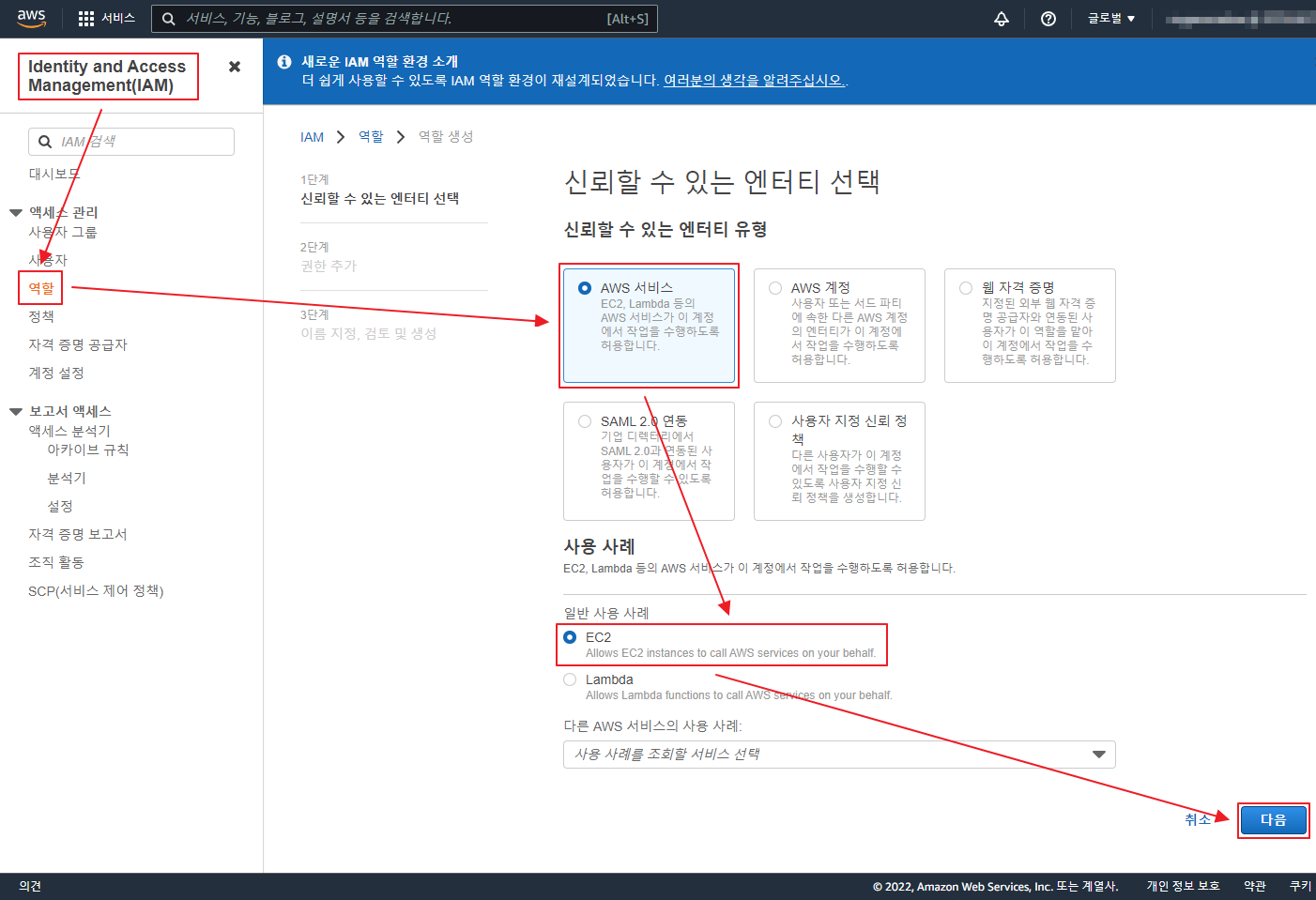
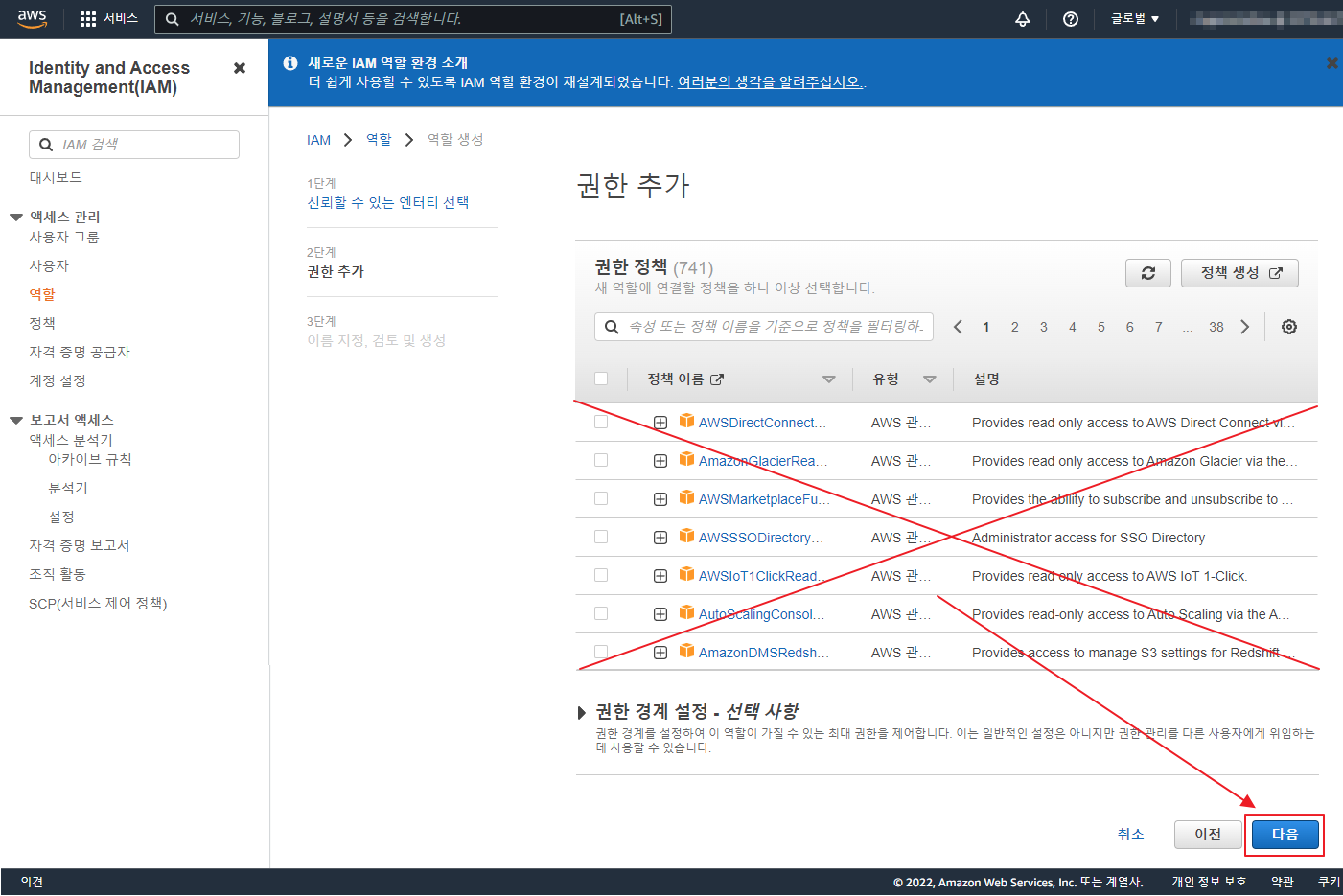
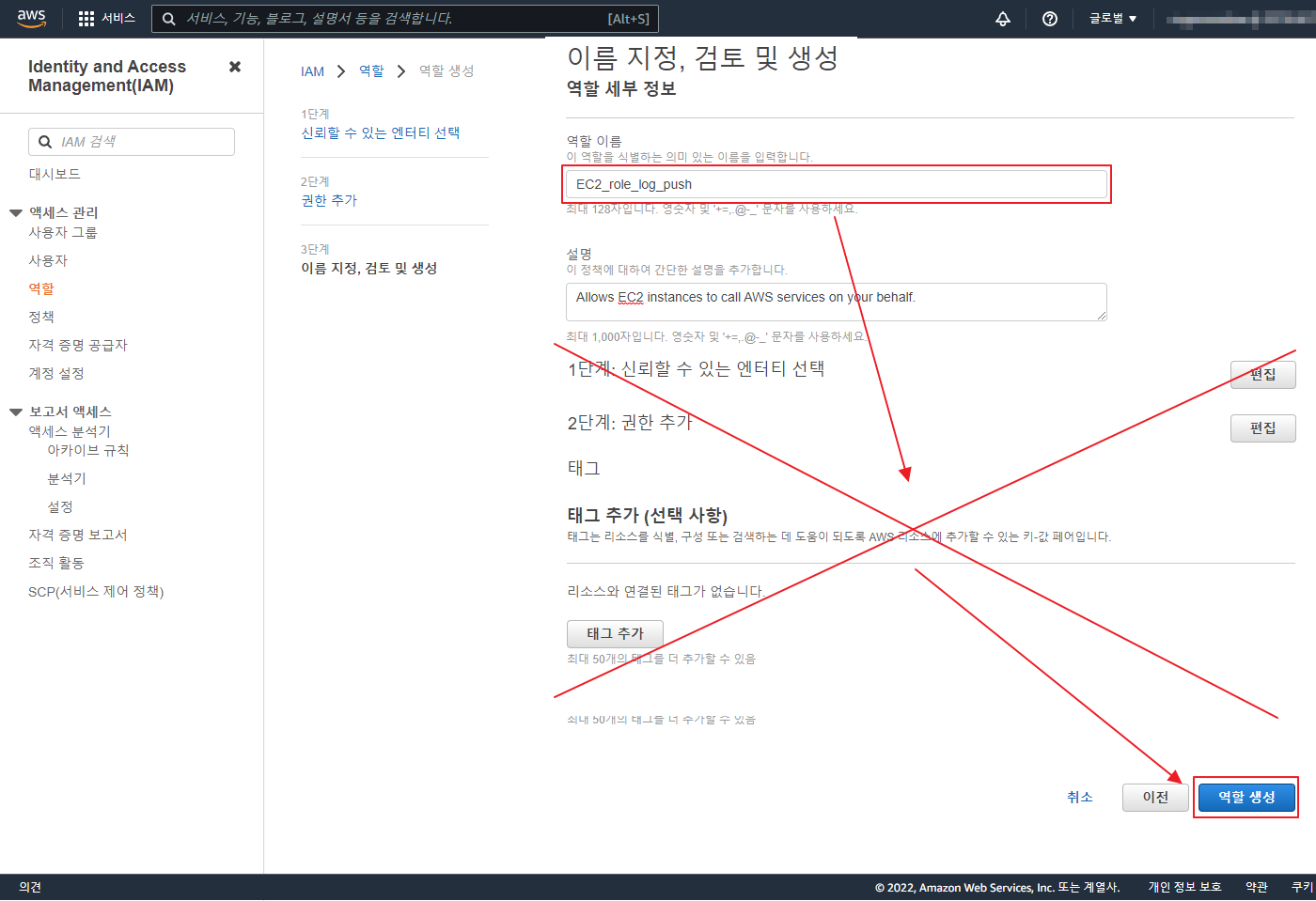
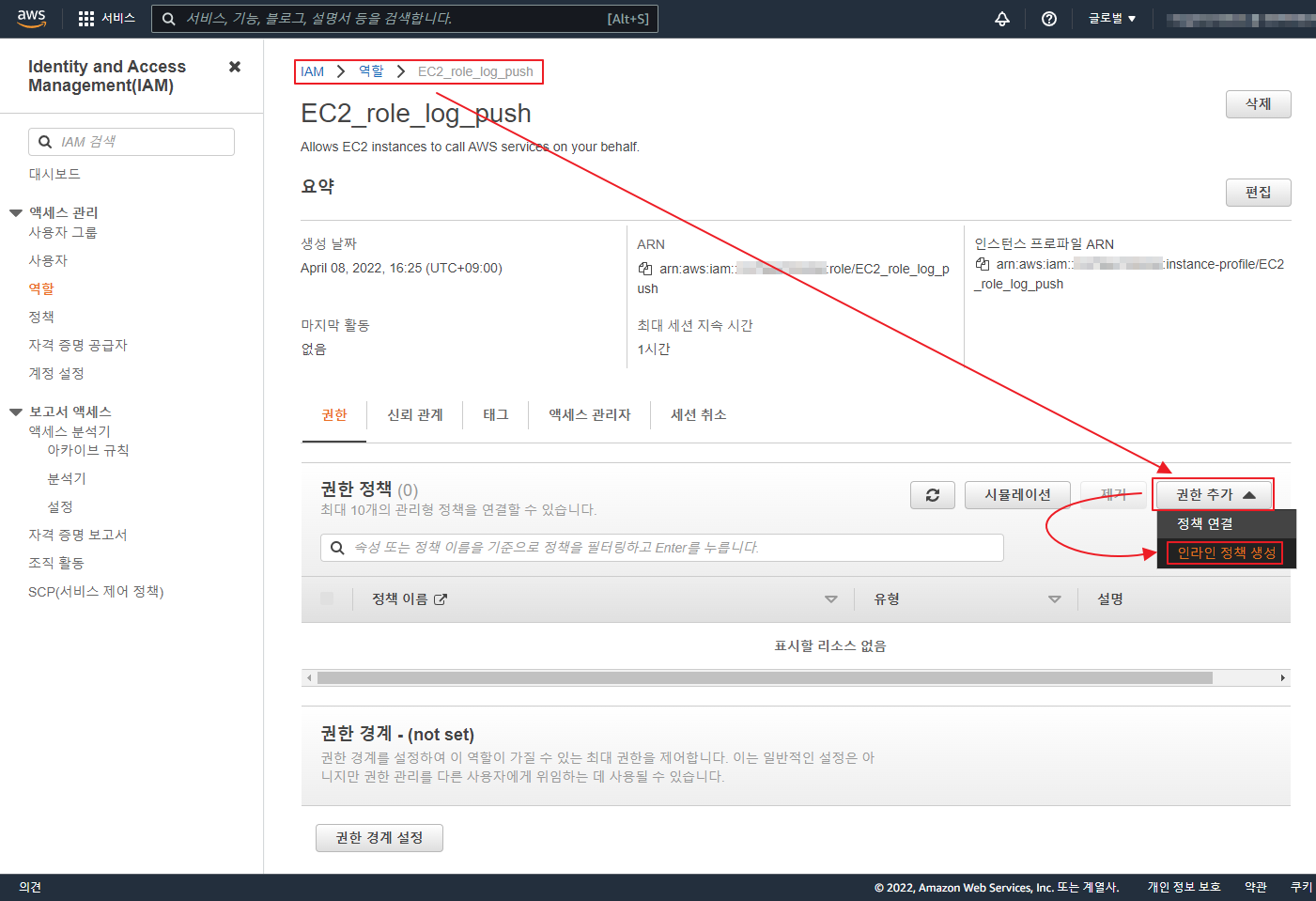
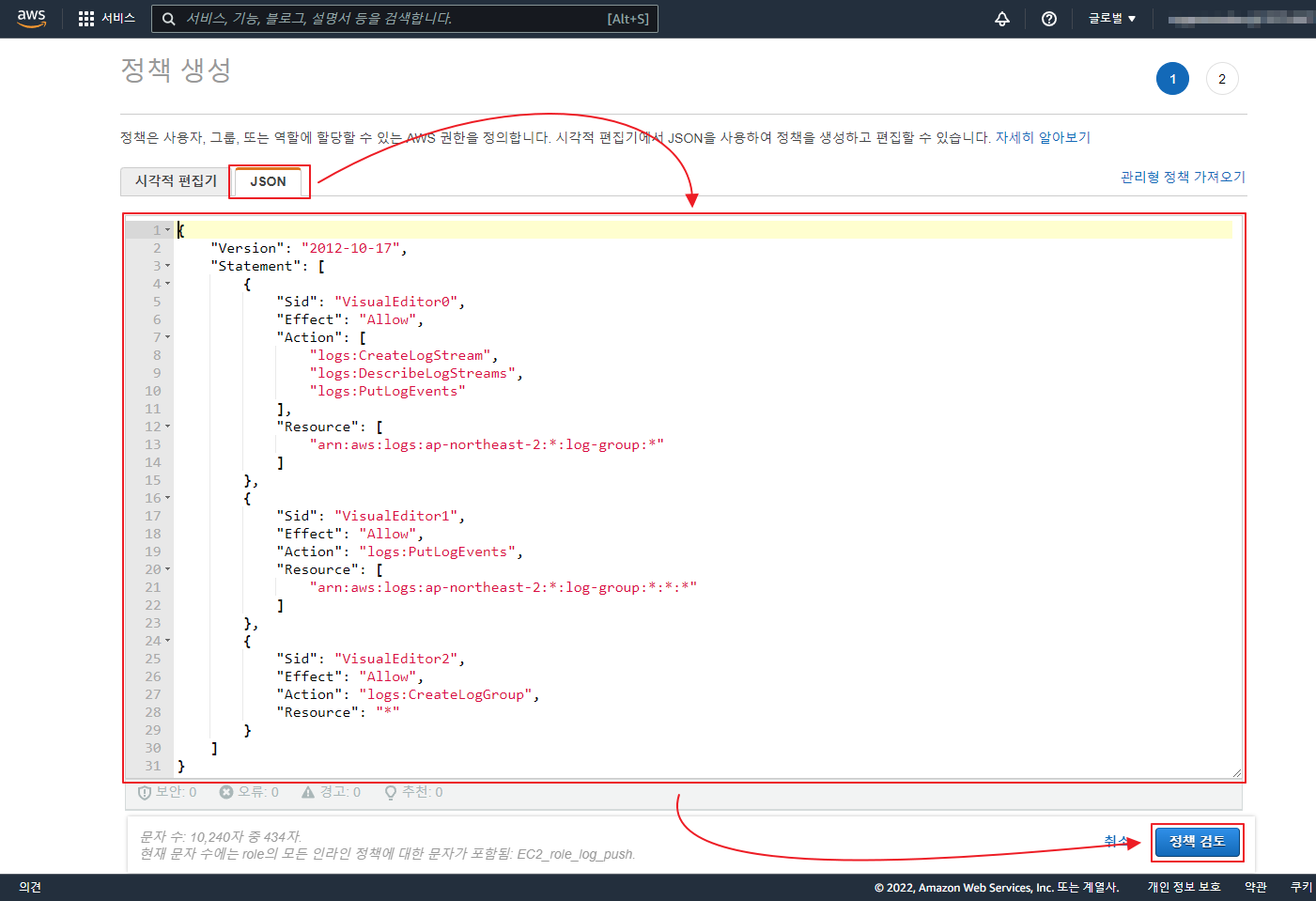
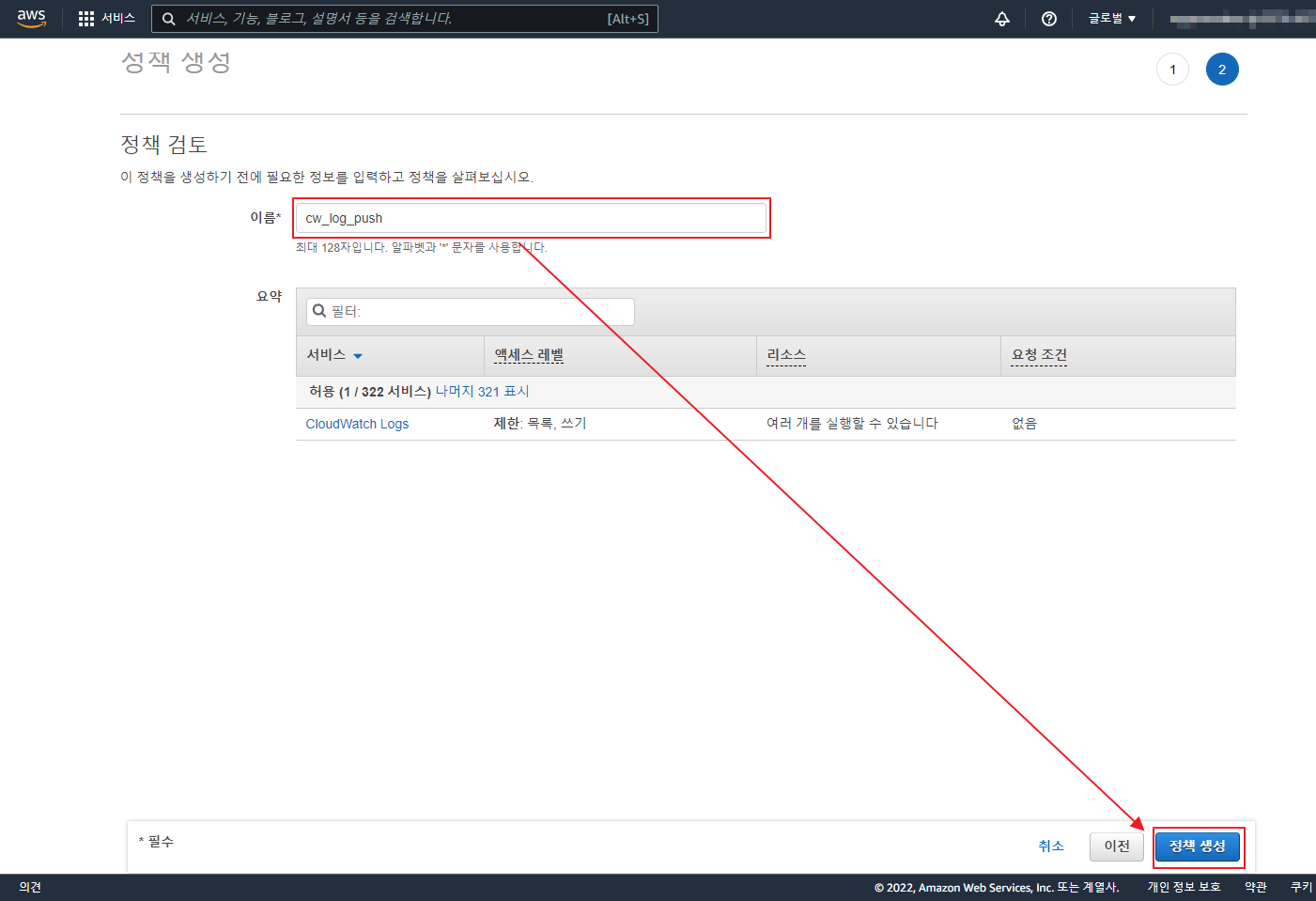
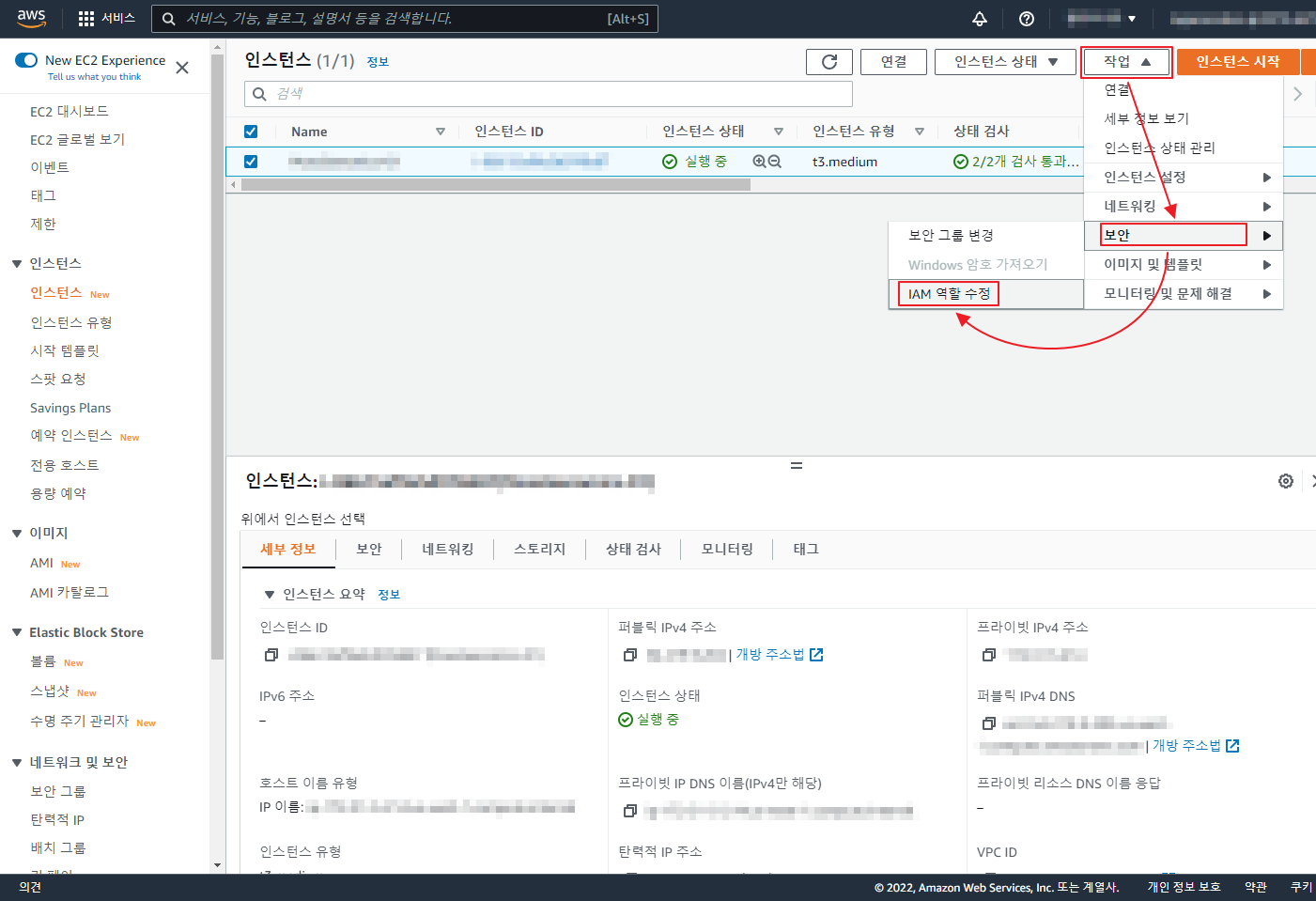
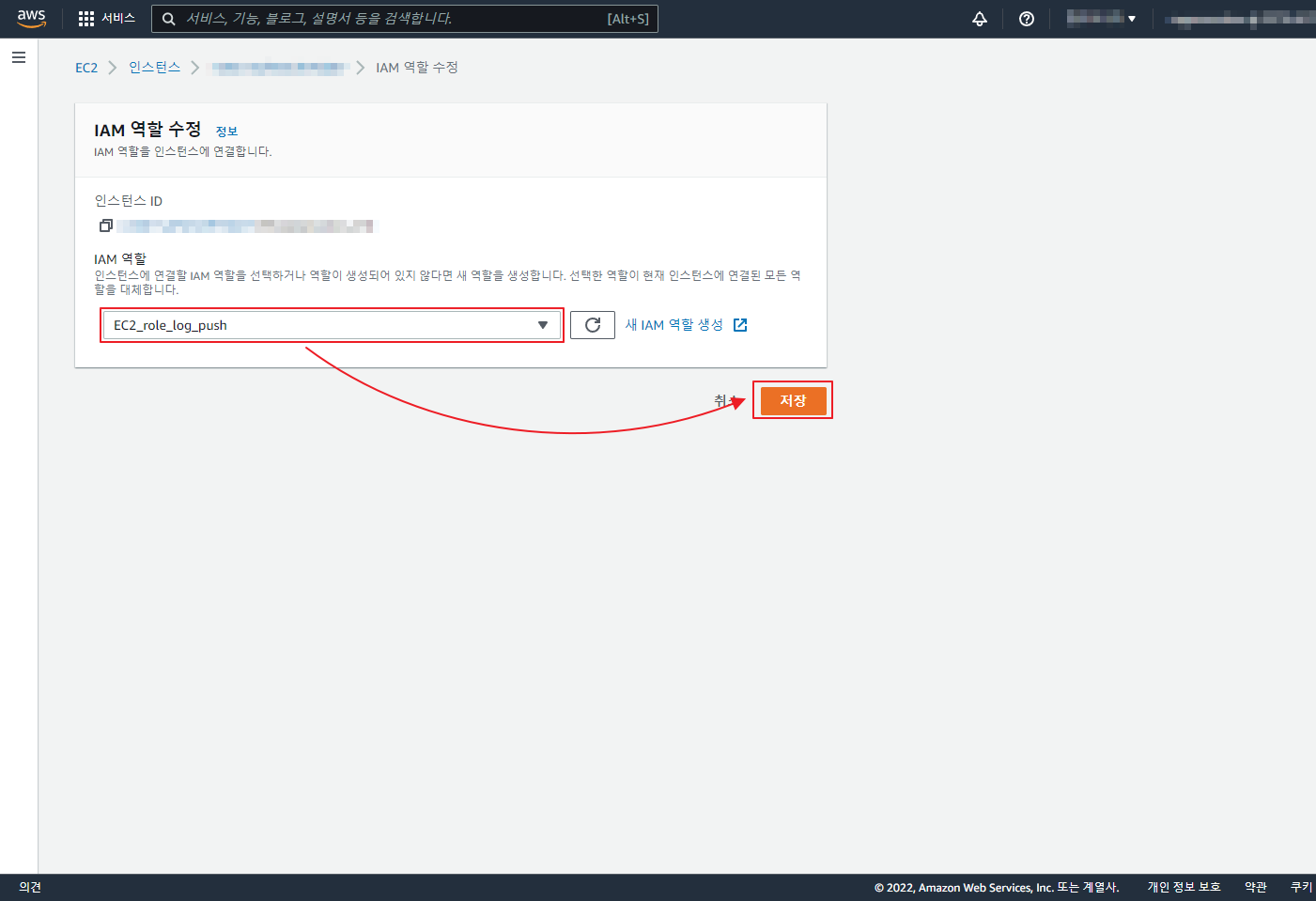
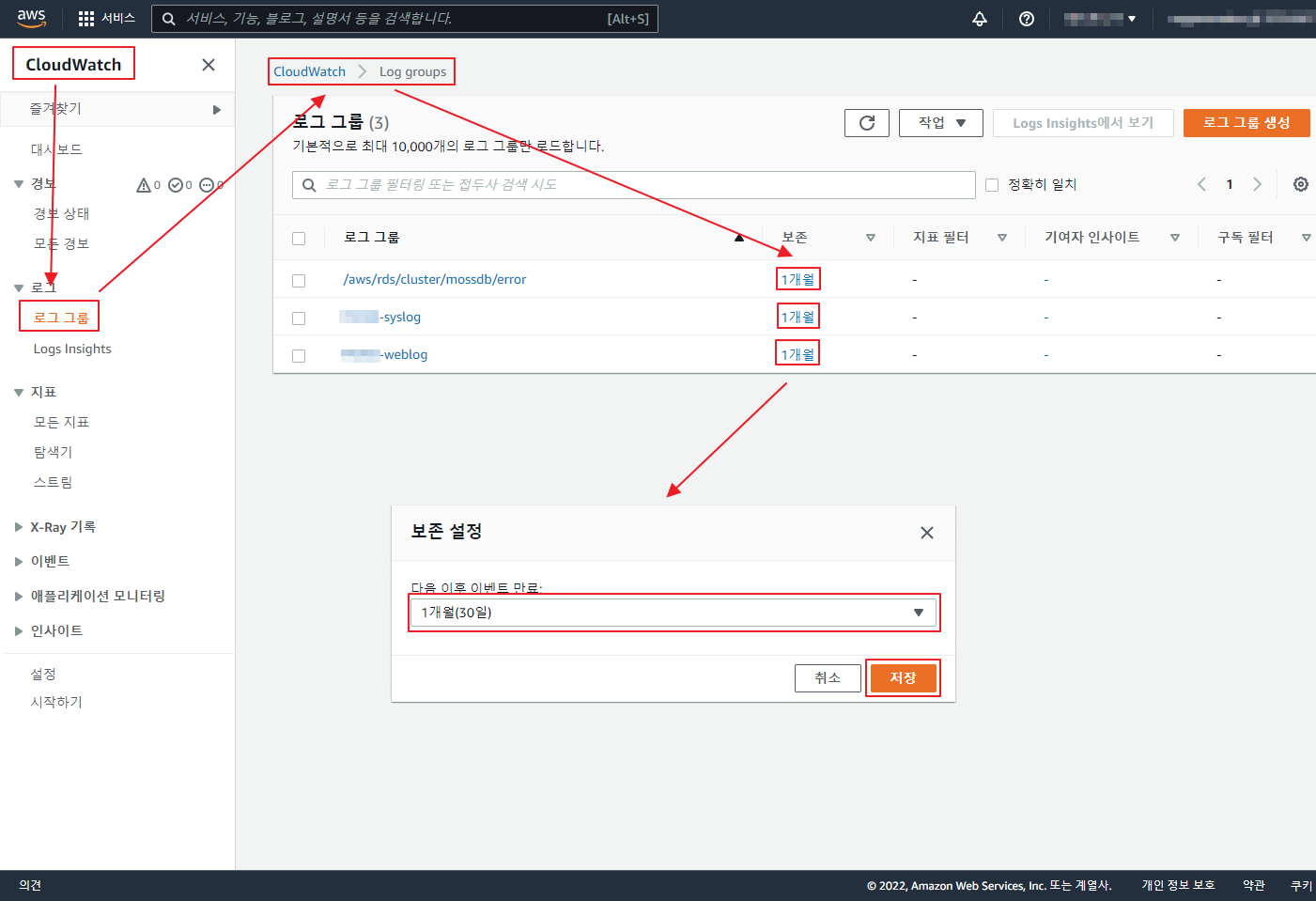
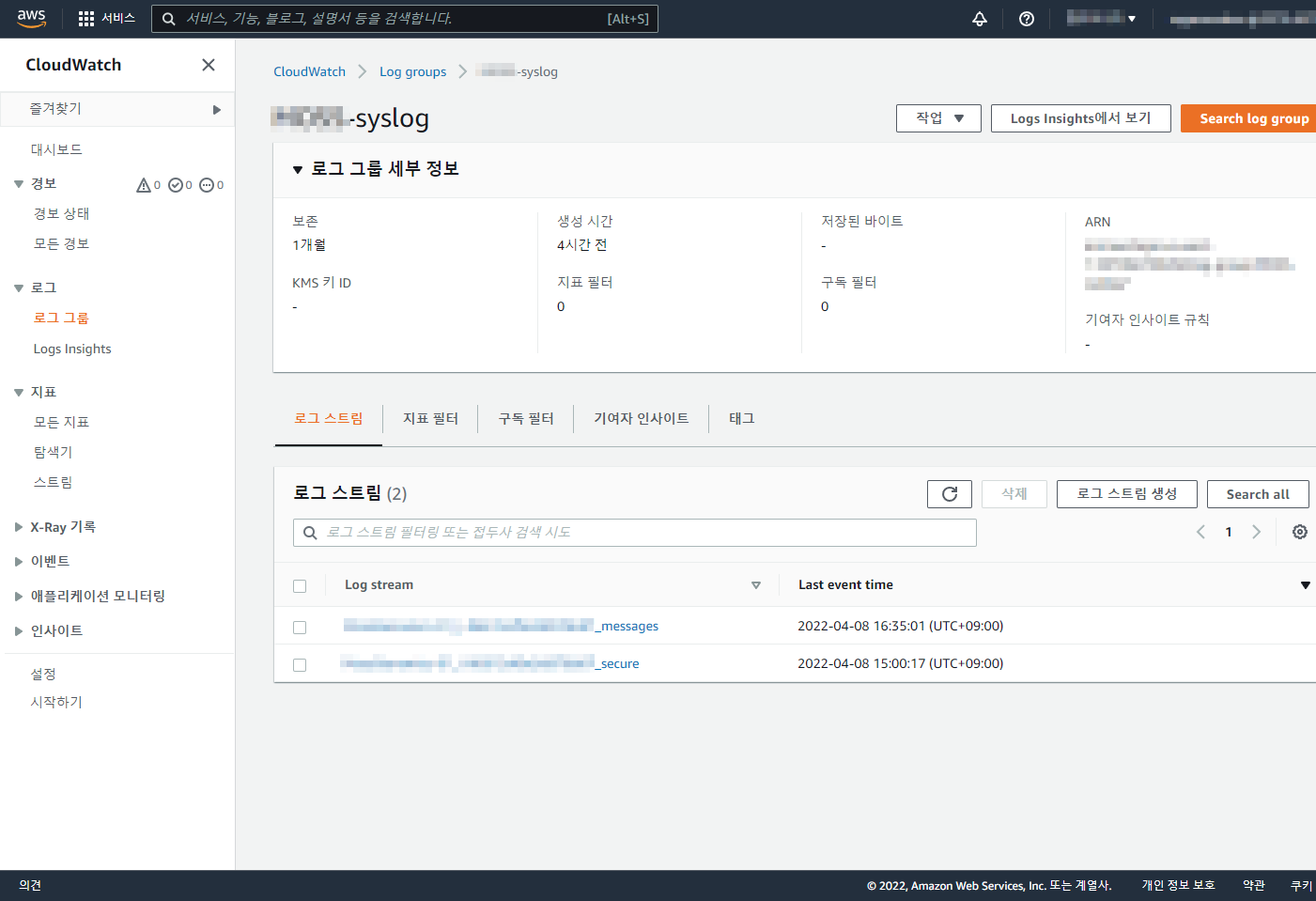
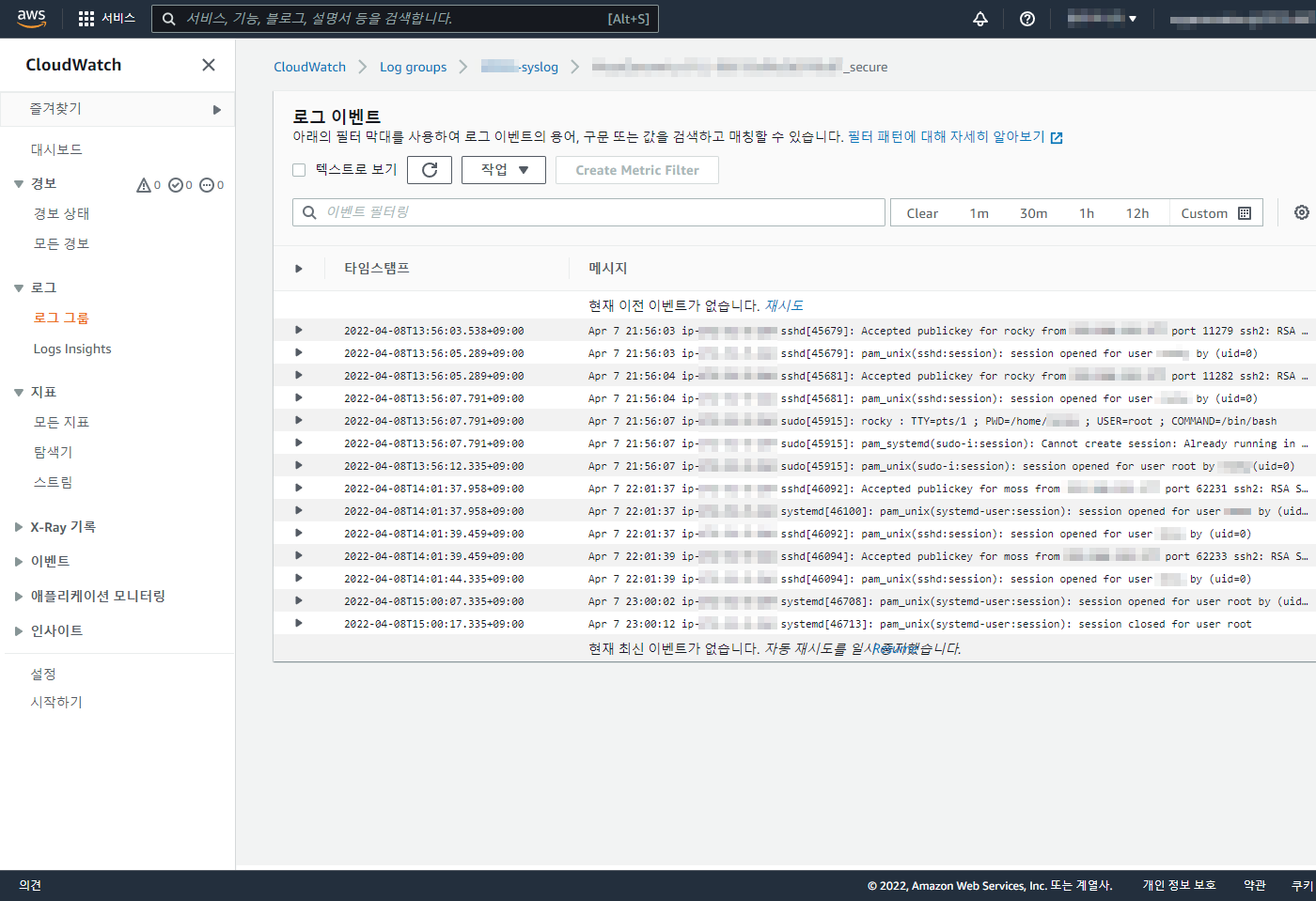
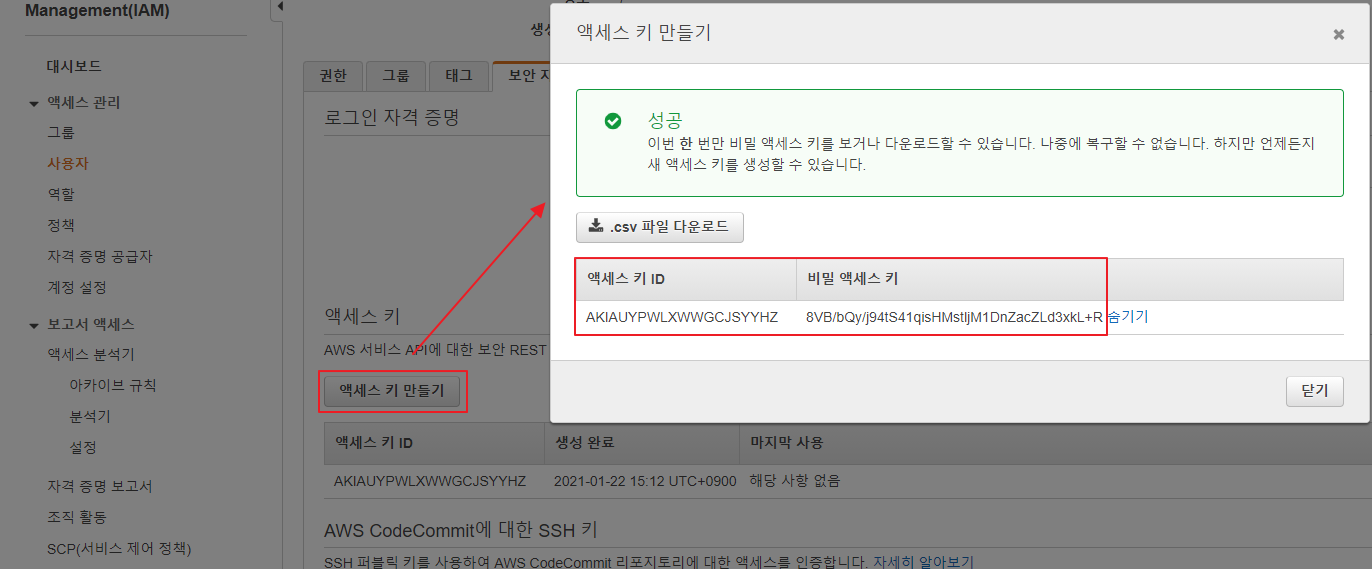
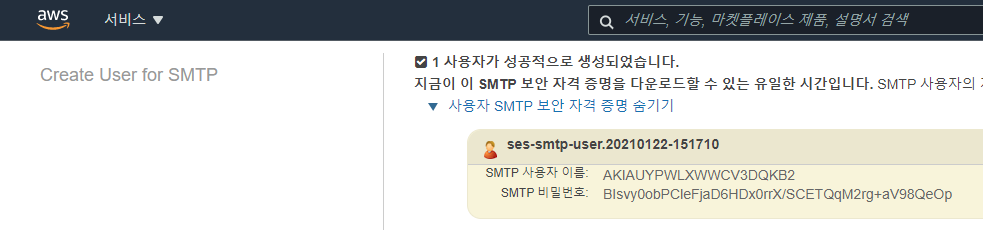
git 은 기본적으로 Synology 에서 Git Server 를 제공 한다.
다만 GUI를 이용한 환경만 제공 하지 않기 때문에 어렵고 불편 하다.
그래서 Synology 서버에 docker 를 설치 하고 gitea 도커이미지를 이용해서 Container 를 띄움으로서 내부용 레포지토리를 운영 한다.
gitea go언어로 만들어져 가볍고 ssh 키 등록 및 http 연결을 잘 지원 하고 일반 사용법도 github와 비슷 하다.
ARM64 환경에서도 잘 되기 때문에 신규 사용자의 Amazon CodeCommit 이 중지된 지금 시점에서 클라우드내에 IaaS 으로 구축해 사용하기도 좋다.
- Synology NAS 에서 docker 또는 Container Manager 를 설치 한다.(DSM 버전에 따라 패키지 명이 다를 수 있다.)
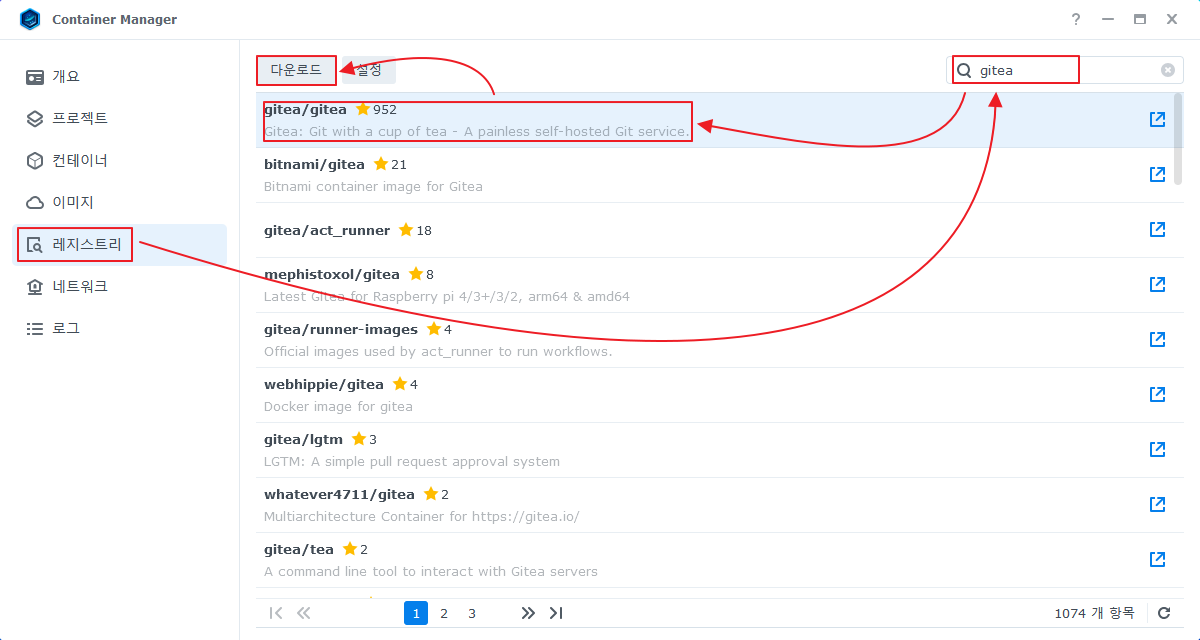
- gitea/gitea 이미지를 다운로드 받는다.
- 다운로드가 완료 되면 이미지를 실행해 시킨다.
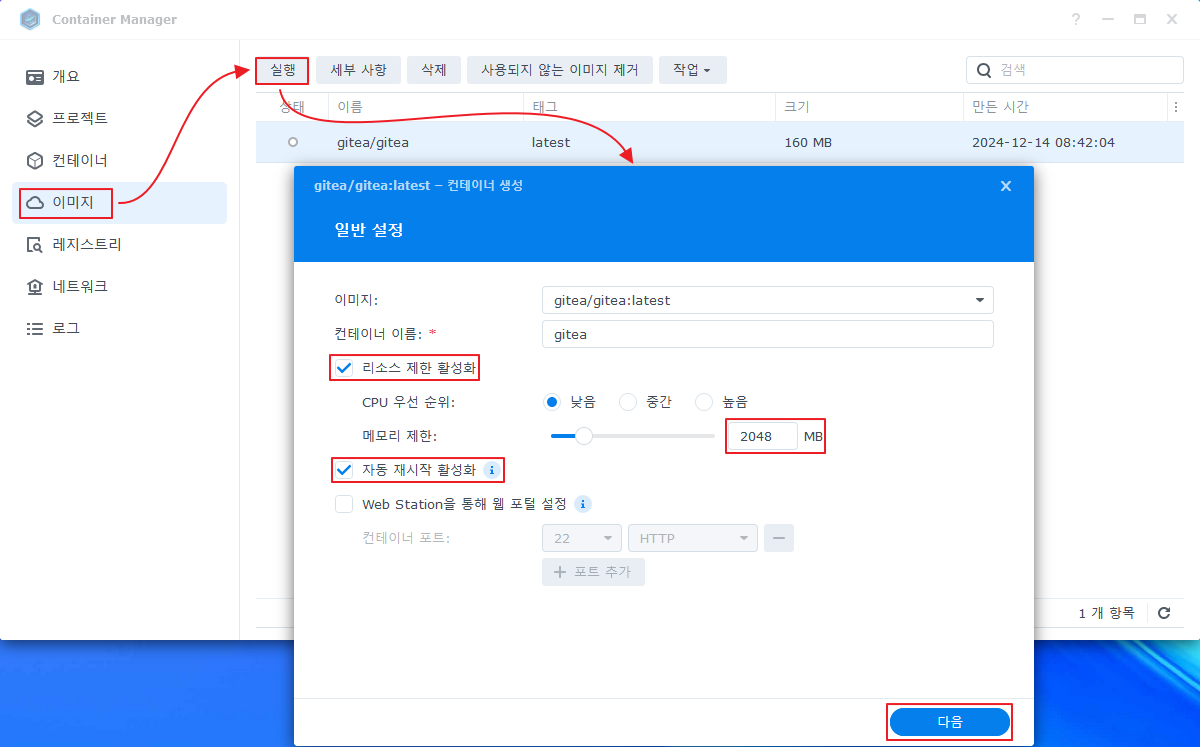
내 경우엔 리소스를 제한하고 자동 재시작 옵션을 활성화 했다.
(gitea 는 golang 으로 만들어져 가볍지만(초기 메모리 사용량 100MB) 레포가 늘어 나면 메모리 사용량이 꾸준히 증가할 수 있다.
- 다음 화면에서 연결될 포트를 선언 한다.
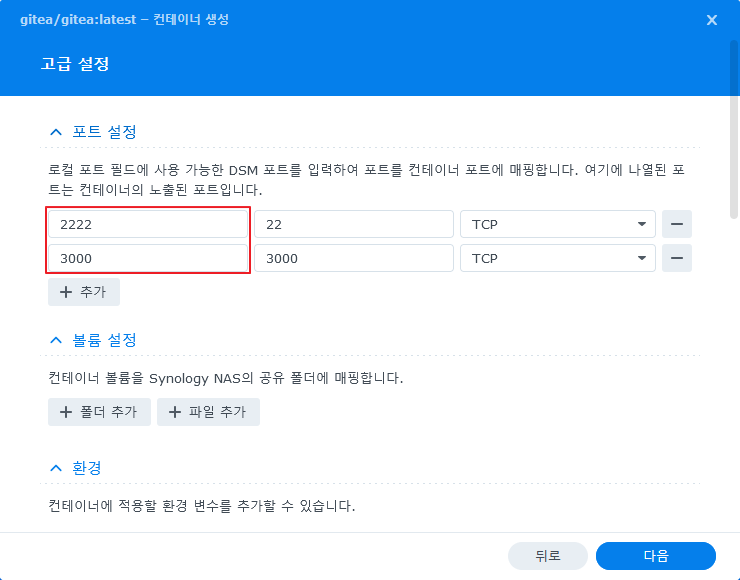
gitea 은 기본적으로 ssh, http 프로토콜을 사용한다.
DSM의 ssh 데몬과 충돌 하지 않도록 포트는 2222 으로 지정 하고 웹 포트는 3000을 사용 하도록 했다.
- 파일 스테이션에서 연결할 폴더를 생성 한다.
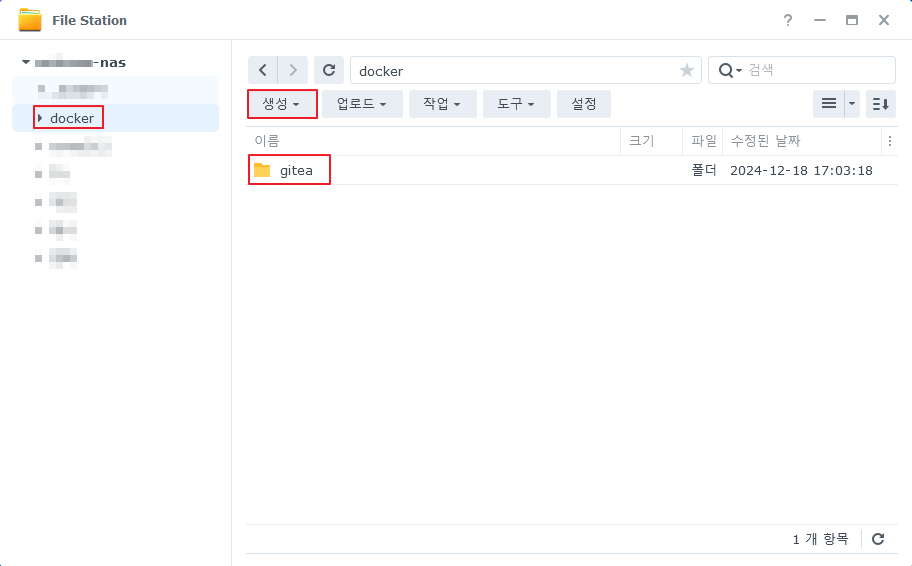
Synology 에서 Container에 볼륨으로 연결될 드라이브는 docker 를 설치시 생성 되는 /docker 공유 폴더 아래에 있어야 권한 문제가 발생하지 않는다.
- 스크롤을 내려서 연결할 볼륨 및 환경을 추가 한다.
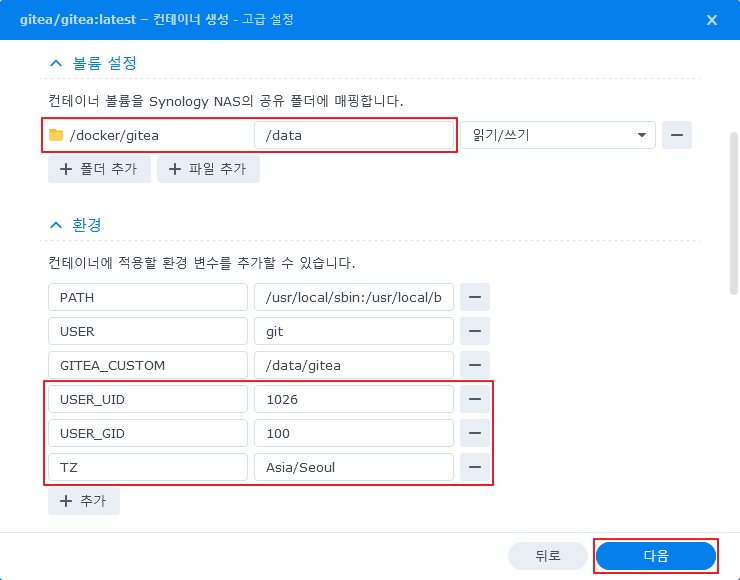
|
1 2 |
nas-admin@synology01:/$ id nas-admin uid=1026(nas-admin) gid=100(users) groups=100(users),101(administrators) |
참고로 내 Synology 의 관리자 아이디는 nas-admin 이 아니다. (쓸모 없는 =_= 공격금지)
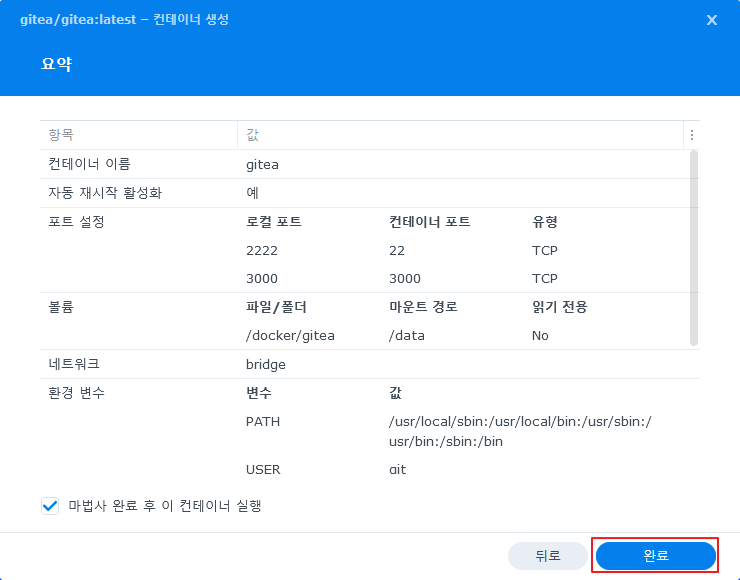
- 설정값 최종 점검 후 완료 버튼을 눌러 실행 한다.
- gitea 으로 접속해 설치를 진행 한다. ( http://[Synology-Nas-IP]:3000 )
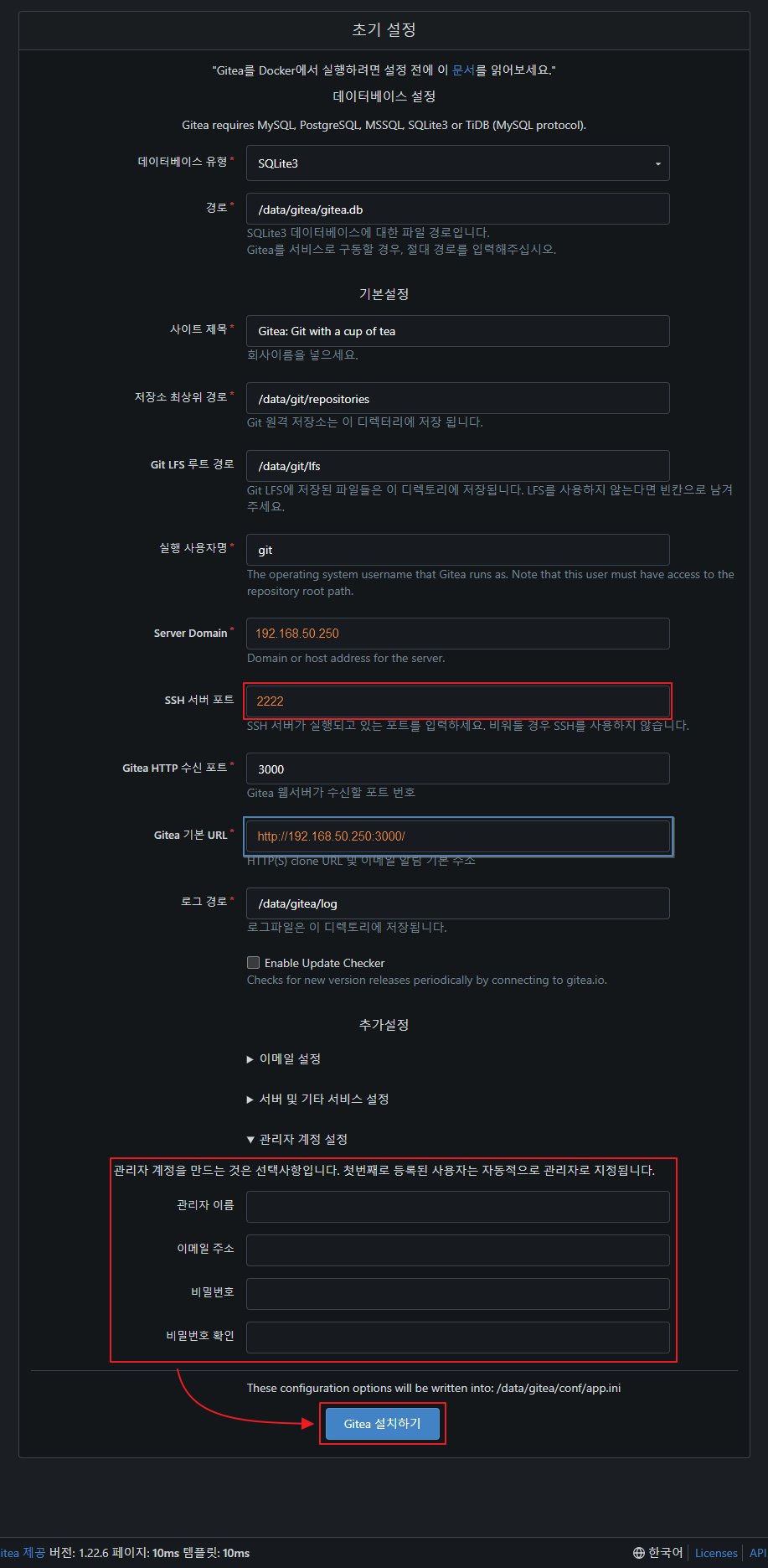
관리자 계정 설정의 ▶ 를 눌러서 관리자 정보를 입력 하는것을 잊지 말자.
중간에 빨간색, 파란색 칸은 Container 를 실행 할때 ssh, http 포트를 입력해야 하는 부분으로 맞추어 주어야 한다.
- 테스트로 github 에 있는 레포지토리를 mirror 으로 생성 해본다.

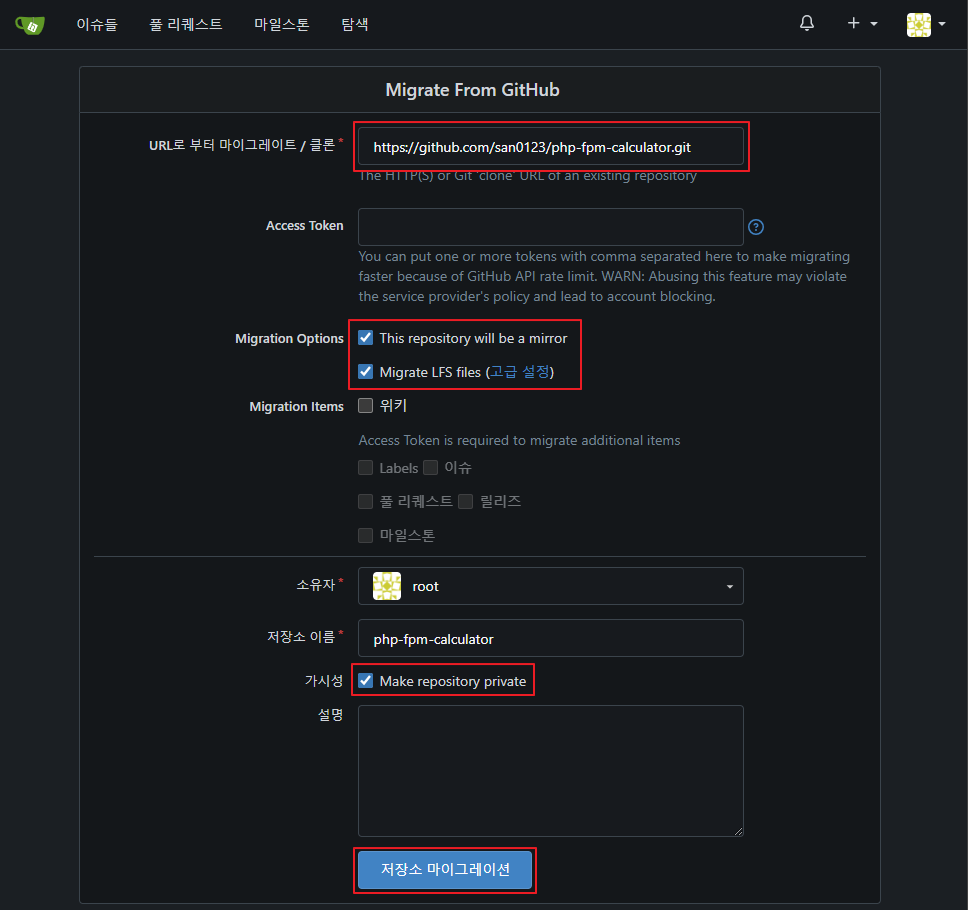
미러로 생성 하는 경우 원본 에서 8시간 마다 원본에서 데이터 싱크를 해온다 ‘ㅅ’a
gitea 의 화면 구성은 github 과 비슷해 어렵지 않을 것이다.
- 설정 변경
설치 화면에서 설정 할 수 있는 부분은 /admin 페이지에서 수정 되지 않는게 대부분 이다.
OPEN ID 차단 이나 회원 가입을 막는 부분등은 아래와 같이 /volume1/docker/gitea/gitea/conf/app.ini 설정 파일을 수정 해야 한다.
|
1 2 3 4 5 6 7 8 |
[service] # 회원가입 차단=true / 허용=false DISABLE_REGISTRATION = true [openid] # OPEN ID 가입/로그인 설정 ENABLE_OPENID_SIGNIN = true ENABLE_OPENID_SIGNUP = true |
container를 사전에 정지 하고 파일 수정 한뒤에 다시 컨테이너를 시작 한다.