그렇다. 또 바뀌었다 ‘ㅅ’….
GeoIP database 파일을 다운 받는데 링크 주소가 변경 되었다
맥스마인드 사이트의 회원 가입 이후 라이선스 키를 받아야 다운로드를 받을 수 있도록 변경 되었다.
crontab 에 아래와 같이 geoipupdate 명령어를 주기적으로 실행 함으로서 업데이트를 실행할 수 있다.
|
1 2 3 4 5 |
~]# crontab -e ------------------------------------------------------ 00 06 * * 5 /bin/geoipupdate # GeoIP database update. ------------------------------------------------------ |
단지 위 명령어를 실행 하기 위해 맥스마인드사의 회원 가입 과 라이선스 키를 발급 받아야 한다.
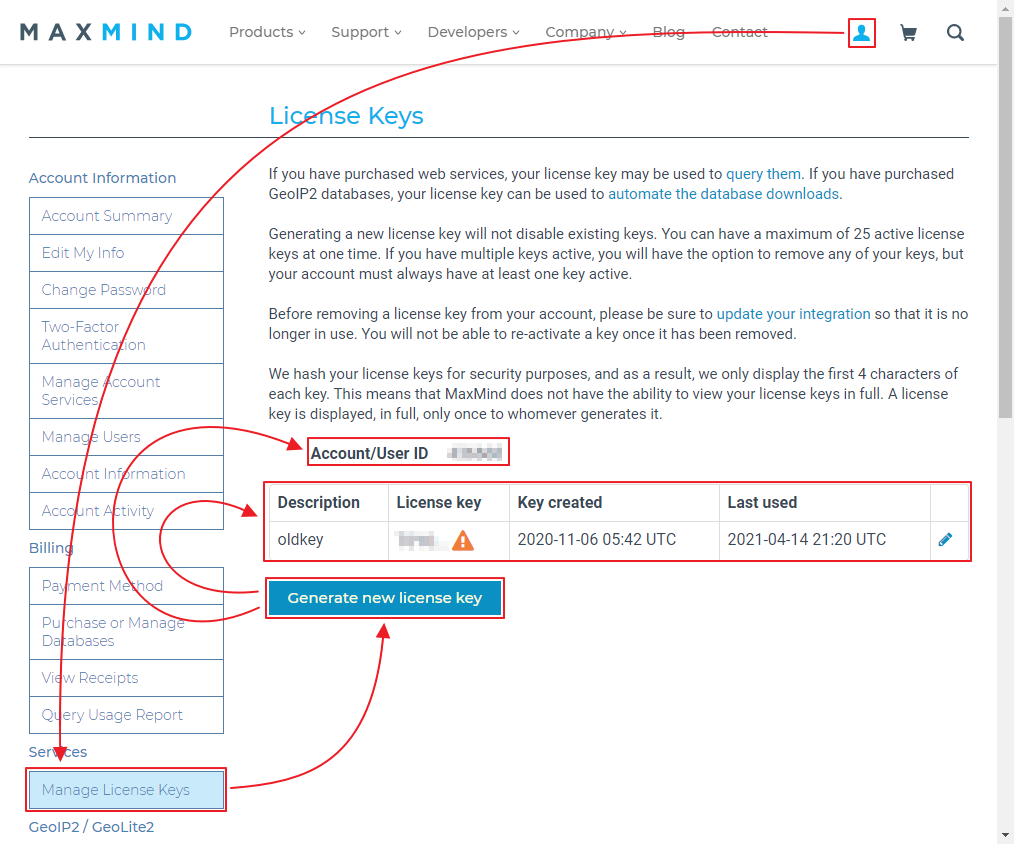
그리고 /etc/GeoIP.conf 파일에서 라이선스키 등록을 진행해야 한다.
|
1 2 |
AccountID 123456 LicenseKey ABCDEFGHIJKL |
이후 geoipupdate명령어를 통해서 업데이트가 잘 되나 실행해보면 된다.
|
1 |
~]# geoipupdate |
출처 : https://dev.maxmind.com/geoip/geoipupdate/
다른 방법으로는 기존 처럼 스크립트를 이용 하여 바뀐 URL 에 파라메터로 라이선스 키를 넣어서 호출하는 방법이 있다.
개인 적으로 남이 만든 프로그램 보단 직접 하는 스크립트를 선호하는 편이라.. (OS 의존성도 없는 편이고 해서 ‘ ㅅ’a)
스크립트 3 번째 줄에 위 방법을 따라 만든 maxmind 라이선스 키를 입력해야 한다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 |
#!/bin/bash ################################# Maxmind_Licensekey="ABCDEFGHIJKL" ################################# CITYDATA="N" ### config - DISABLE city it'll be need free memory 2GB ### geoip set GEOIPDIR="/usr/share/GeoIP" DATALINK="/usr/share/xt_geoip /var/lib/GeoIP" ### avoid overlap lockfile=/var/lock/$(basename $0) if [ -f $lockfile ];then P=$(cat $lockfile) if [ -n "$(ps --no-headers -f $P)" ];then exit 1 fi fi echo $$ > $lockfile trap 'rm -f "$lockfile"' EXIT ### define server are primary or secandary. ### install dependances if [[ -z $(which git) ]];then sudo yum -y install git > /dev/null 2>&1 ;fi if [[ -z $(which pip) ]];then sudo yum -y install python2-pip > /dev/null 2>&1;fi if [[ -z $(pip list|grep pygeoip) ]];then sudo pip install pygeoip > /dev/null 2>&1 ;fi if [[ -z $(pip list|grep ipaddr) ]];then sudo pip install ipaddr > /dev/null 2>&1 ;fi ### link path if [[ ! -d $GEOIPDIR ]];then mkdir -p $GEOIPDIR fi for a in $DATALINK do if [[ ! -d $a ]];then if [[ $(readlink $a) != $GEOIPDIR ]];then rm -rf $a;ln -s $GEOIPDIR $a fi;fi done ### https://github.com/sherpya/geolite2legacy - csv to data file. cd $GEOIPDIR if [ ! -e $GEOIPDIR/geolite2legacy/geolite2legacy.py ];then cd $GEOIPDIR git clone https://github.com/sherpya/geolite2legacy.git fi ### make GeoIP.dat files from GeoLite2 CSV file. if [ -d $GEOIPDIR/geolite2legacy ];then cd $GEOIPDIR/geolite2legacy EXT="zip" CIF="GeoLite2-City-CSV" COF="GeoLite2-Country-CSV" BASEURL="https://download.maxmind.com/app/geoip_download?edition_id" COF_URL="$BASEURL=$COF&license_key=$Maxmind_Licensekey&suffix=$EXT" ORI_DATE=$(date +"%Y%m%d%H%M.%S" -d "$(curl -sI $COF_URL|grep -i ^Last-Modified:|cut -d, -f2)") CSV_DATE=$(date +"%Y%m%d%H%M.%S" -d "$(stat -c %y $COF.$EXT)") if [[ "$ORI_DATE" != "$CSV_DATE" ]];then rm -f $COF.$EXT $CIF.$EXT wget "$COF_URL" -O $COF.$EXT >/dev/null 2>&1 if [ -s $GEOIPDIR/geolite2legacy/$COF.$EXT ];then python geolite2legacy.py --input-file $COF.$EXT --fips-file geoname2fips.csv --output-file GeoIP.dat python geolite2legacy.py --input-file $COF.$EXT -6 --fips-file geoname2fips.csv --output-file GeoIPv6.dat fi if [[ $CITYDATA == "Y" ]];then CIF_URL="$BASEURL=$CIF&license_key=$Maxmind_Licensekey&suffix=$EXT" wget "$CIF_URL" -O $CIF.$EXT >/dev/null 2>&1 python geolite2legacy.py --input-file $CIF.$EXT --fips-file geoname2fips.csv --output-file GeoLiteCity.dat python geolite2legacy.py --input-file $CIF.$EXT -6 --fips-file geoname2fips.csv --output-file GeoLiteCityv6.dat touch -t $ORI_DATE GeoLiteCity.dat GeoLiteCityv6.dat mv -f Geo{LiteCity,LiteCityv6}.dat $GEOIPDIR/ >/dev/null 2>&1 fi touch -t $ORI_DATE GeoIP.dat GeoIPv6.dat $COF.$EXT mv -f Geo{IP,IPv6}.dat $GEOIPDIR/ >/dev/null 2>&1 fi fi exit 0 |
기존 스크립트에서 추가 변경된 기능이 있는데 DB 업데이트가 이루어 졌는지 배포주소의 HEAD 체크를 통해서 Last-Modified 를 체크 한다.
쉽게 말하면 맥스마인드사에서 새로운 db를 업데이트 할때만 작동 한다는 소리다. ( 더 쉽게: 매일 돌리면 된다. )
때문에 위 스크립트는 /etc/cron.daily/ 폴더내에 넣어두면 필요할 때 자동 실행이 된다.
출처 : https://dev.maxmind.com/geoip/geoip-direct-downloads/#Direct_Downloads