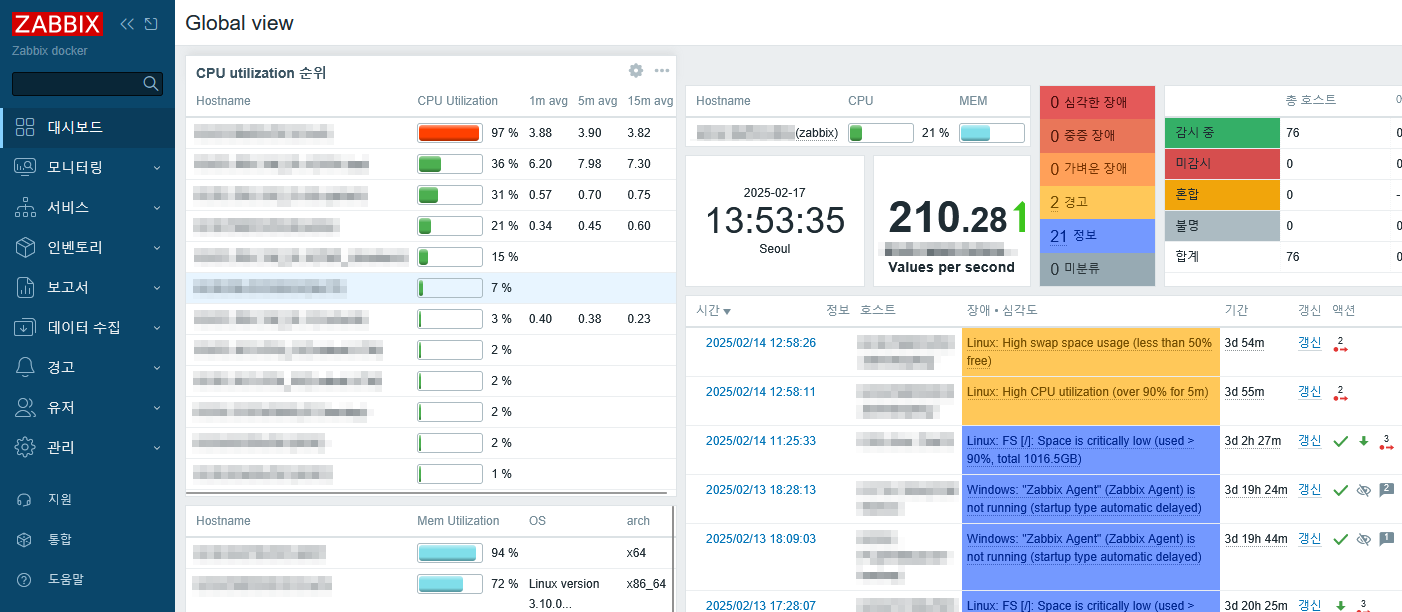
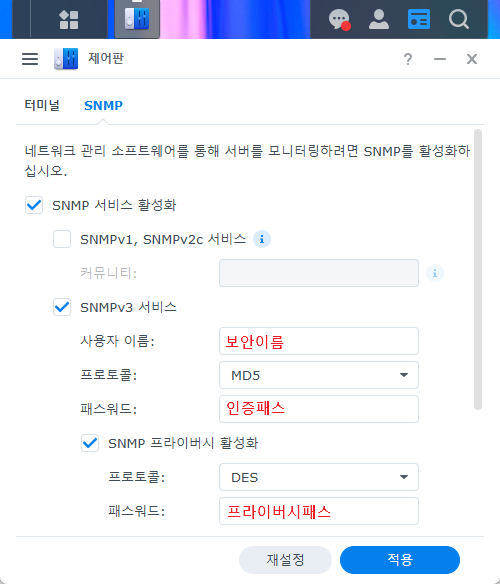
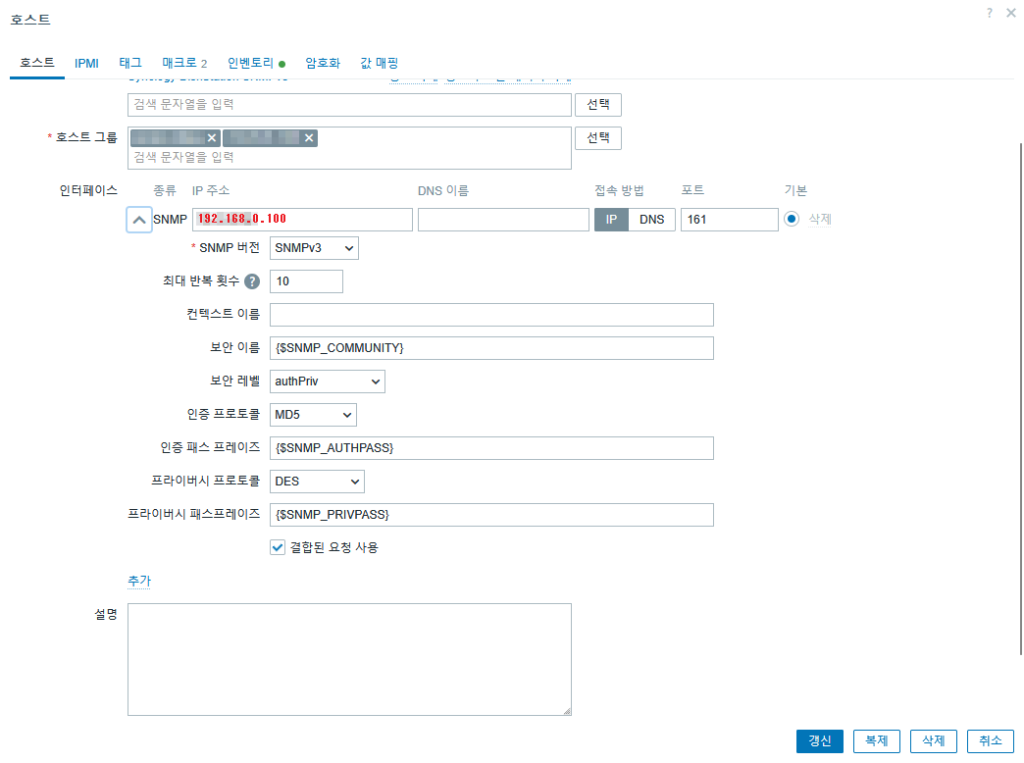
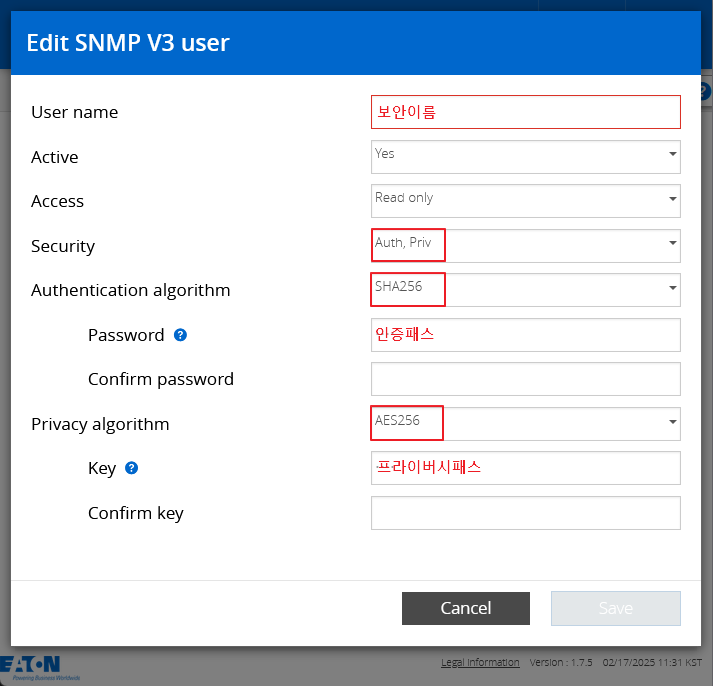
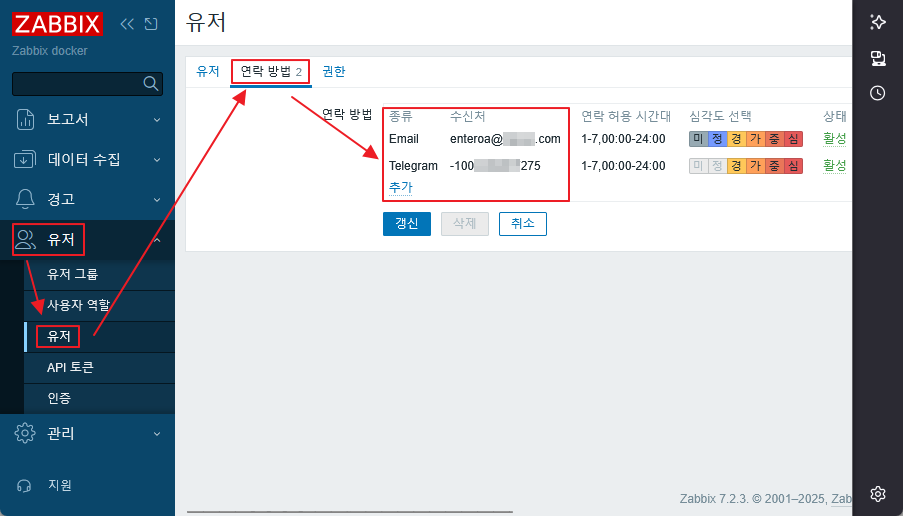
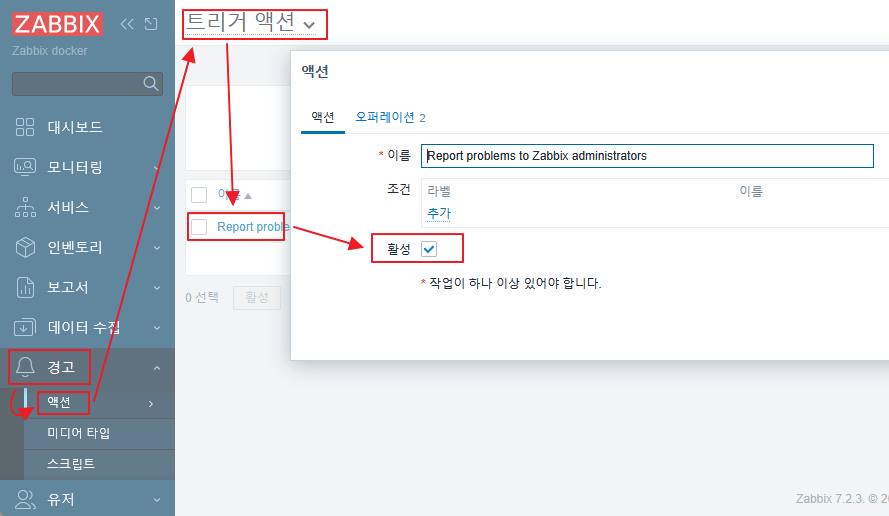
감시대상에 zabbix-agent2 를 설치 했다면 아래와 같이 추가 플러그인을 통해서 좀더 상세한 감사를 할 수 있다.
Centos는 6 이상 부터 zabbix-agent2 를 사용할 수 있고, Ubuntu는 18.04 이상 부터 zabbix-agent2 를 사용할 수 있다.
1. docker
docker.sock 파일 권한을 주어야(usermod) 하기 때문에 zabbix 계정의 서브 그룹으로 docker 를 추가 해야 작동 한다.
|
|
~]# sudo -u zabbix zabbix_agent2 -c /etc/zabbix/zabbix_agent2.conf -t docker.containers cannot fetch data: get "http://1.28/info": dial unix /var/run/docker.sock: connect: permission denied. ~]# usermod -aG docker zabbix ~]# systemctl restart zabbix-agent2.service |
2. smartctl 을 이용한 디스크 장애 사전 탐지
물리적인 HDD 가연결된 서버의 경우 smartctl 을 설치 해서 디스크의 장애를 사전에 탐지할 수 있다.(가상 서버는 불필요 하겠지 ‘ㅅ’a)
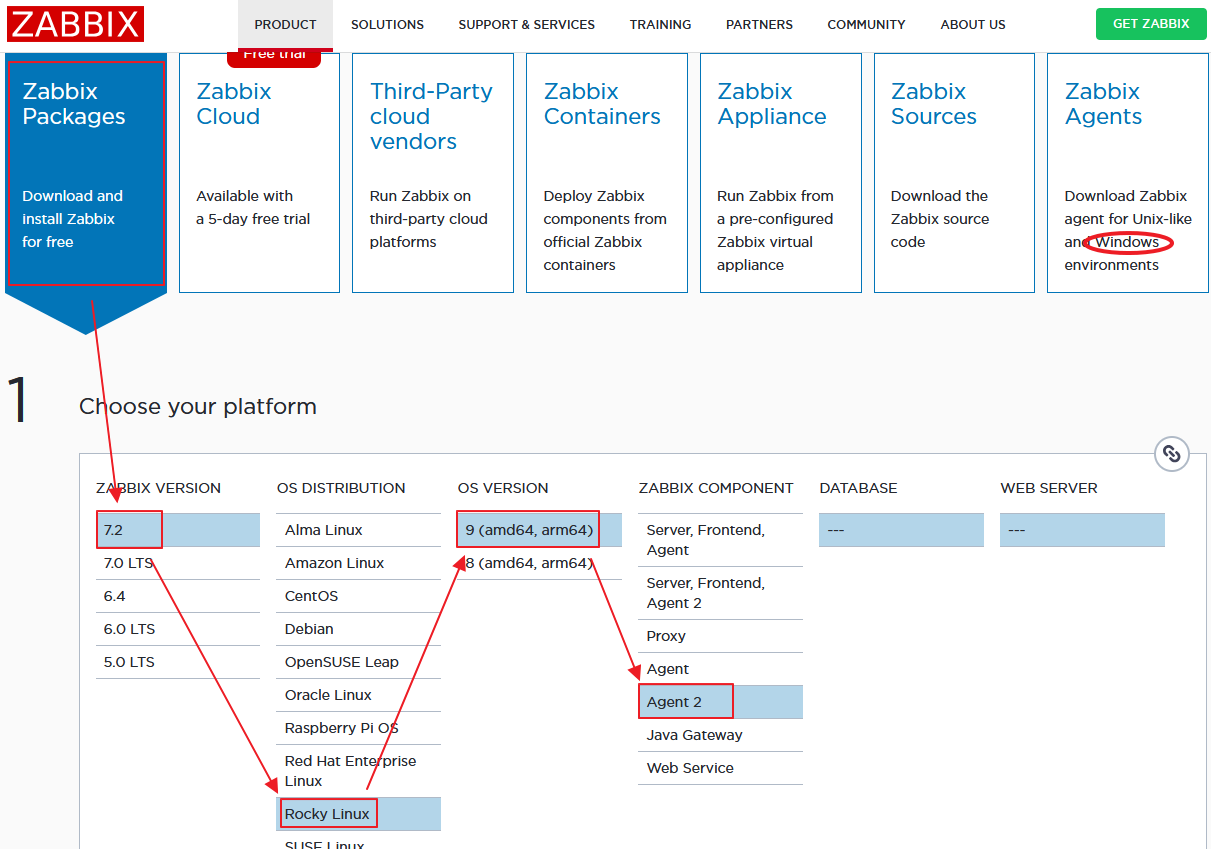
smartctl v7.1 이상을 요구 하기 때문에 Ubuntu 18.04 이상 // Rockylinux/Almalinux 8 이상에서 사용이 가능 하며 아래의 명령어로 설치 할 수 있다.
|
|
~]# dnf install -y smartmontools ~]# smartctl -V smartctl 7.1 2019-12-30 r5022 [x86_64-linux-5.11.0-34-generic] (local build) |
zabbix 계정에 smartctl 명령어 위치를 확인하고 password 없이 smartctl 사용 권한을 부여 한다.
|
|
~]# which smartctl /usr/sbin/smartctl ~]# vi /etc/sudoers.d/zabbix |
|
|
Cmnd_Alias SMARTCTL = /usr/sbin/smartctl zabbix ALL= (ALL) NOPASSWD: SMARTCTL Defaults!SMARTCTL !logfile, !syslog, !pam_session |
smartctl 명령어 및 zabbix_agent2 명령어를 실행해서 테스트를 하고 정상적 이라면 zabbix-agent2 서비스를 재시작 한다.
|
|
~]# smartctl --scan ~]# smartctl -a /dev/sda ~]# sudo -u zabbix zabbix_agent2 -c /etc/zabbix/zabbix_agent2.conf -t smart.disk.discovery ~]# systemctl restart zabbix-agent2.service |
https://sourceforge.net/projects/smartmontools/files/ 에서 smartmontools-7.4-1.win32-setup.exe 설치 파일을 받아 설치 한다.
워드패드를 관리자 권한으로 실행 한뒤에 C:\Program Files\Zabbix Agent 2\zabbix_agent2.d\plugins.d\smart.conf 파일을 불러와서 Plugins.Smart.Path을 다음과 같이 수정 한다.
|
|
Plugins.Smart.Path=C:\PROGRA~1\SMARTM~1\bin\smartctl.exe |
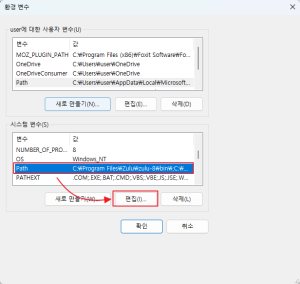
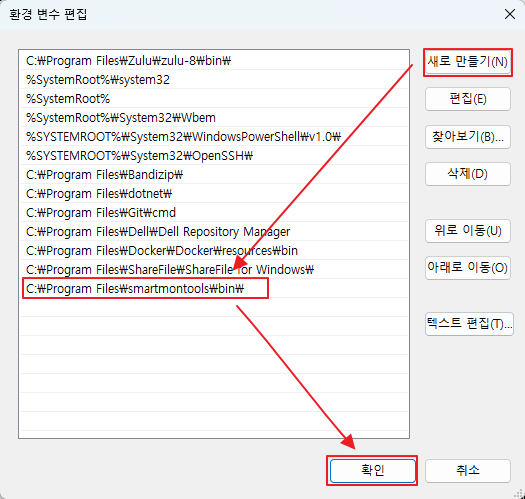
설치 파일(exe)을 설치 할때 %PATH%를 유져로 잡아주기 때문에 그냥 cmd 나 smartctl 에서의 명령어 사용은 문제가 없지만 zabbix agent 2 서비스에서 호출을 해야 하기 때문에 다음 그림과 같이 시스템 변수로 %PATH% 를 잡아준다.
powershell 을 관리자 모드로 실행 해서 테스트를 하고 정상적 이라면 zabbix-agent2 서비스를 재시작 한다.
|
|
PS C:\> smartctl --scan PS C:\> smartctl -a /dev/sda PS C:\> cd 'C:\Program Files\Zabbix Agent 2\' PS C:\> .\zabbix_agent2.exe -t smart.disk.discovery PS C:\> Get-Service -DisplayName "Zabbix Agent 2" | Restart-Service |
- zabbix-server 콘테이너 안에서 zabbix_get 으로 클라이언트에 호출을 할 수 있다. (포트 10051)
|
|
~]# docker exec -it zabbix-server bash :~$ zabbix_get -s [감시대상IP] -k [smart.disk.get | smart.disk.discovery | smart.attribute.discovery] :~$ zabbix_get -s 192.168.0.110 -k smart.disk.discovery |
호출을 했을때 마지막에
exit status 2 는 zabbix-agent2 가 smartctl 을 실행 할 수 없는 경우이다. 리눅스의 경우 sudo 권한 윈도우의 경우 path 가 문제일 가능성이 높다.
exit status 4 코드가 발생할 경우 디스크의 S.M.A.R.T 가 꺼져 있어서 확인할 수 없는 경우 이다. (레이드카드<->smartctl 호환성 문제)
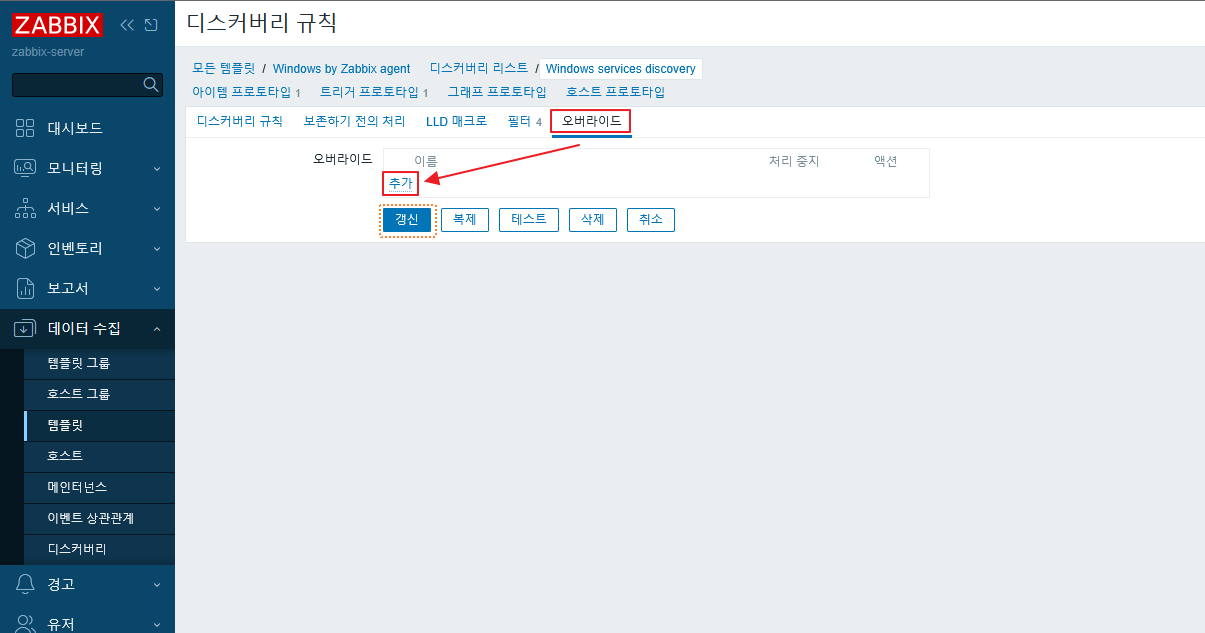
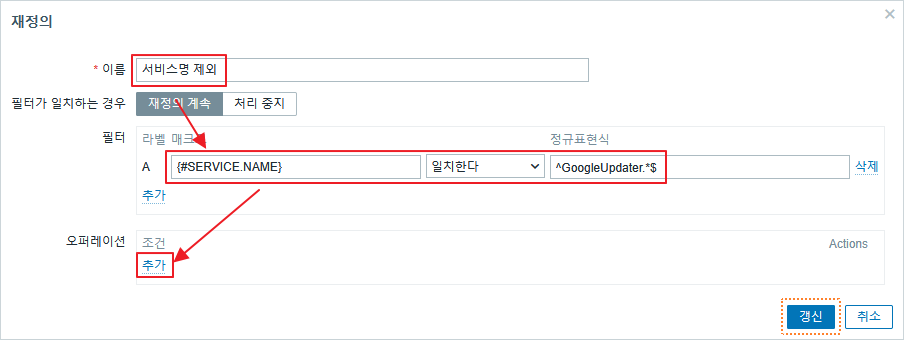
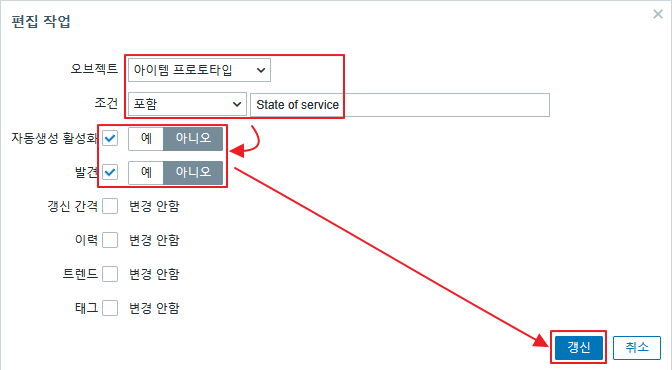
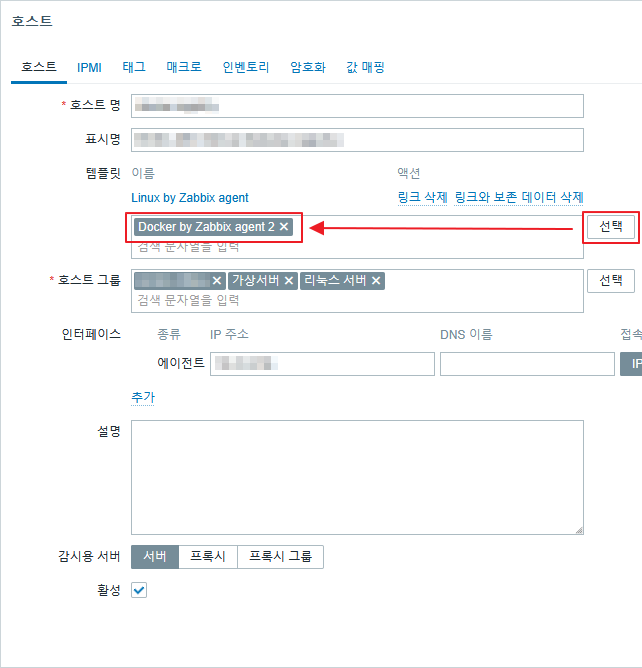
zabbix 관리자 화면에서 생성된 호스트 템플릿에 SMART by zabbix agent 2를 추가 한다.
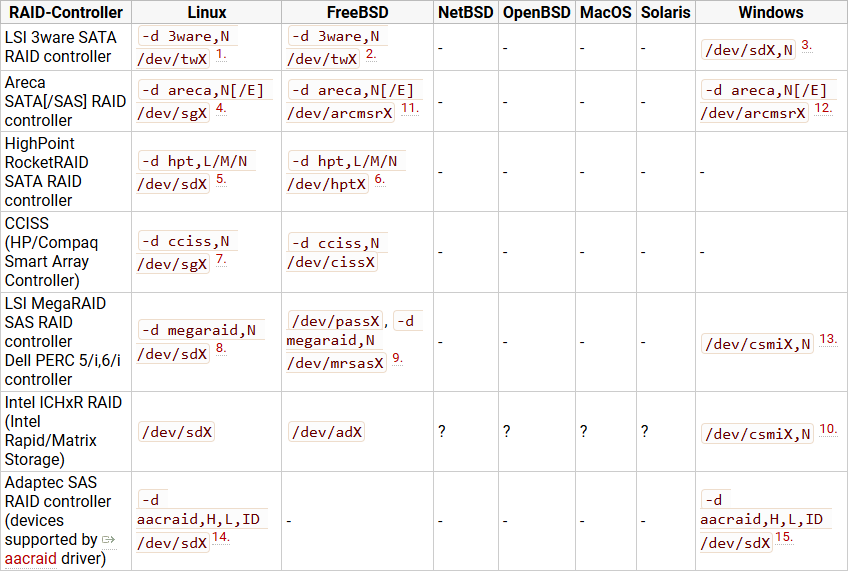
위 표를 보면 알겠지만 Linux에서는 대부분 지원 하지만 Windows 일 경우 지원하는 하드웨어가 좀 한정적이다.
smartmontools 버전이 7.0 이하 일때는….
지원되지 않는 OS 일경우 smartctl 명령어를 최신버전을 컴파일 해서 설치 한다. (gcc-c++, make 가 설치되어 있어야 한다.)
(Rockylinux 8.5 에서는 smartctl 버전이 7.1 이지만 정상 동작 하지 않았고 7.4를 깔면 동작이 가능했다.)
메뉴얼: https://www.smartmontools.org/wiki/Download#Installfromthesourcetarball
다운로드: https://sourceforge.net/projects/smartmontools/files/
|
|
~]# cd /opt ~]# tar xvfzp smartmontools-7.4.tar.gz ~]# cd smartmontools-7.4 ~]# ./configure ~]# make ~]# make install |
make install 을 하면 centos 7 기준 으로 /usr/local/sbin/smartctl 위치에 설치 된다.
sudo 권한 부여 및 /etc/zabbix/zabbix_agent2.d/plugins.d/smart.conf 파일을 수정한다.
|
|
~]# echo "zabbix ALL=(ALL) NOPASSWD: /usr/local/sbin/smartctl" > /etc/sudoers.d/zabbix ~]# sed -i "s+# Plugins.Smart.Path=+Plugins.Smart.Path=/usr/local/sbin/smartctl+g" /etc/zabbix/zabbix_agent2.d/plugins.d/smart.conf |
레이드 카드가 달린 HP 서버 linux 에서는 cciss 으로 명령어를 수집을 하긴 하는데 문제가 발생 하였다.
명령어 호출을 어찌하는지 아래 명령어로 확인 하는데만 26초가 소요가 되었다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
~]# zabbix_agent2 -t smart.disk.discovery -v |grep "executing smartctl command" sudo -n smartctl -j -V sudo -n smartctl --scan -j sudo -n smartctl --scan -d sat -j sudo -n smartctl -a /dev/nvme0 -j sudo -n smartctl -a /dev/nvme1 -j sudo -n smartctl -a /dev/sda -d 3ware,0 -j sudo -n smartctl -a /dev/sda -d areca,1 -j sudo -n smartctl -a /dev/sda -d cciss,0 -j sudo -n smartctl -a /dev/sda -d sat -j sudo -n smartctl -a /dev/sda -d scsi -j sudo -n smartctl -a /dev/sdb -d 3ware,0 -j sudo -n smartctl -a /dev/sdb -d areca,1 -j sudo -n smartctl -a /dev/sdb -d cciss,0 -j sudo -n smartctl -a /dev/sdb -d sat -j sudo -n smartctl -a /dev/sdb -d scsi -j ... ... |
서버에 존재하지도 않는 3ware, areca 등을 호출하면서 에러메세지 리턴을 json 으로 파싱하면서 많은 시간을 쓴다는걸 확인 하였고 다음과 같이 해결 하였다.
먼저 위 명령어를 참조 해서 정상적인 동작을 하는 명령어를 찾는다. (SMART 가 Enabled 으로 나오는 명령어를 찾는다)
|
|
~]# smartctl -a /dev/sda -d cciss,0 ... Serial number: WB0000F1 SMART support is: Enabled ... ~]# smartctl -a /dev/sdb -d cciss,1 ... Serial number: WB0000GG SMART support is: Enabled ... |
zabbix agent 가 실행하는 명령어를 보면 nvme0, nvme1 호출은 정상적이다.
하지만 sdb 는 cciss,1 이 아닌 cciss,0 으로만 호출했기 때문에 정상 호출이 안되어서 인식하지 못한다.
그래서 그에 대응할 수 있도록 sd[x] -d scsi에 반응 하도록 하고 스 이외 명령어 실행은 빠르게 종료 되도록 exit 2로 반환 하도록 스크립트를 만들어 적용 한다.
|
|
~]# mkdir -p /etc/zabbix/script ~]# touch /etc/zabbix/script/smartctl_enteroa ~]# chmod 755 /etc/zabbix/script/smartctl_enteroa |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
#!/usr/bin/env bash # RAID HPE P408i-a SR Gen10 1.34 # /dev/nvme0 -d nvme # /dev/nvme1 -d nvme # /dev/sda -d scsi -> /dev/sda -d cciss,0 # /dev/sdb -d scsi -> /dev/sdb -d cciss,1 # /dev/sdc -d scsi -> /dev/sdc -d cciss,2 # /dev/sdd -d scsi -> /dev/sdd -d cciss,3 # /dev/sde -d scsi -> /dev/sde -d cciss,4 ########################################################## #SMARTCTL=/usr/local/sbin/smartctl SMARTCTL=/usr/sbin/smartctl # need to change to fit the Server. RAIDCARD=cciss # need to change to fit the Server. #RAIDCARD=areca #RAIDCARD=3ware if [[ -n $(awk '/-j -V/{print} /nvme/{print} /scsi/{print} /--scan -j/{print}/--scan -d sat -j/{print}' <<< $@) ]];then ### only run with scsi but it change to cciss,[X] $SMARTCTL $(sed "s/sda -d scsi/sda -d $RAIDCARD,0/g; s/sdb -d scsi/sdb -d $RAIDCARD,1/g; s/sdc -d scsi/sdc -d $RAIDCARD,2/g; s/sdd -d scsi/sdd -d $RAIDCARD,3/g; s/sde -d scsi/sde -d $RAIDCARD,4/g" <<< $@) else exit 2 fi exit 0 |
sudo 권한에 생성한 스크립트의 실행 권한을 추가 한다.
|
|
zabbix ALL=NOPASSWD: /usr/sbin/smartctl, /etc/zabbix/script/smartctl_enteroa |
/etc/zabbix/zabbix_agent2.d/plugins.d/smart.conf 에서 만든 스크립트을 실행하도록 한다.
|
|
Plugins.Smart.Path=/etc/zabbix/script/smartctl_enteroa |
zabbix agent 2 를 재시작 한다.
|
|
~]# systemctl restart zabbix-agent2.service |
Dell 서버에서는 또 다른 문제가 확인이 되었다.
디스크가 12개 정도 주렁주렁 달린 서버의 경우 위와 같은 방법으로 스크립트만 별도 작성해서 적용 하였을때에도 반환 속도가 4 ~ 7초 정도로 확인이 되었다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
#!/usr/bin/env bash # Dell - Broadcom / LSI MegaRAID SAS 2208 [Thunderbolt] (rev 05) # /dev/bus/0 -d megaraid,0 # /dev/bus/0 -d megaraid,1 # ... # ... # /dev/bus/0 -d megaraid,10 # /dev/bus/0 -d megaraid,11 ########################################################## SMARTCTL=/usr/local/sbin/smartctl ### 3ware,0 / areca,1 / cciss,0 / sat / scsi / megaraid if [[ -n $(awk '/-j -V/{print} /--scan -j/{print} /--scan -d sat -j/{print} /megaraid/{print}' <<< $@) ]];then $SMARTCTL $@ else exit 2 fi exit 0 |
smartctl 호출했을때 시간이 3초를 넘어가는 경우 Timeout occurred while gathering data 라는 메세지를 log 에서 확인이 가능하다.
/etc/zabbix/zabbix_agent2.conf 및 /etc/zabbix/zabbix_agent2.d/plugins.d/smart.conf 에 Timeout=, PluginTimeout=, Plugins.Smart.Timeout= 옵션이 있으나
설정해도 3초가 넘어가면 시간 초과로 데이터 수집이 되지 않는다. (유명무실한 옵션….)
|
|
~]# docker exec zabbix-server time zabbix_get -s 192.168.0.200 -p 10050 -k smart.disk.discovery ... ... infomation ... real 0m 4.19s user 0m 0.00s sys 0m 0.00s |
3. mysql
감시 대상 DB에 zbx_monitor 용 어카운트를 생성해야 한다.
|
|
~]# mysql -h127.0.0.1 -uroot -p mysql password: 루트패스워드 |
|
|
MySQL [mysql]> CREATE USER 'zbx_monitor'@'::1' IDENTIFIED BY '비밀번호'; MySQL [mysql]> GRANT PROCESS, SHOW DATABASES, BINLOG MONITOR, SHOW VIEW, SLAVE MONITOR ON *.* TO 'zbx_monitor'@'::1'; -- 권한 부여 후 zbx_monitor 으로 접속을 하지 못할경우 접속 호스트를 % 으로 한다. MySQL [mysql]> RENAME USER 'zbx_monitor'@'::1' TO 'zbx_monitor'@'%'; MySQL [mysql]> FLUSH PRIVILEGES; |
이후 웹 UI – 호스트 설정 에서 다음과 같이 템플릿 Mysql by Zabbix agent 2을 추가 한다.
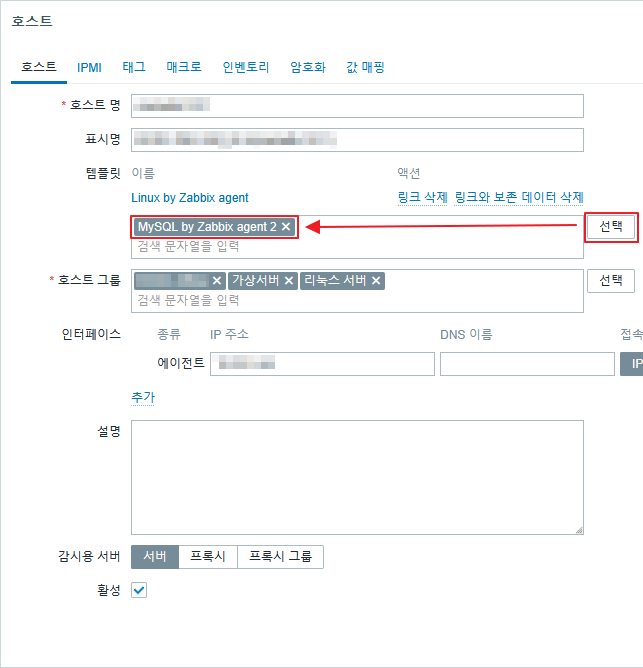
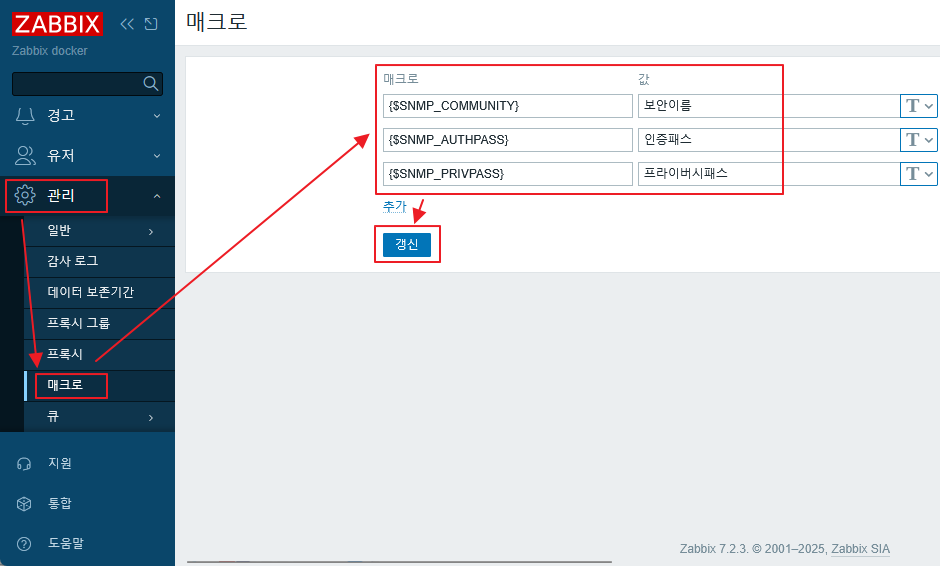
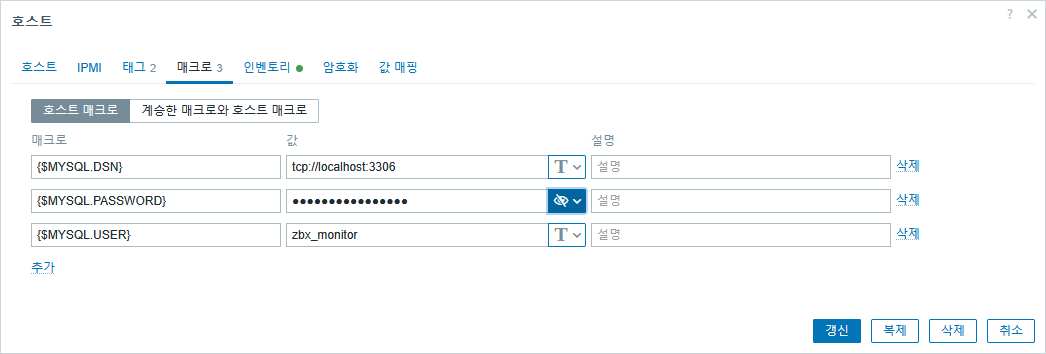
메크로 메뉴로 이동해서 다음과 같이 {$MYSQL.DSN}, {$MYSQL.USER}, {$MYSQL.PASSWORD}을 입력 한다. (관리 > 매크로 로는 설정이 되지 않는 부분이다.)
DSN 에는 tcp://localhost:3306을 입력하고, 패스워드는 텍스트 => 비밀 문자 형식으로 하여 보이지 않도록 한다.
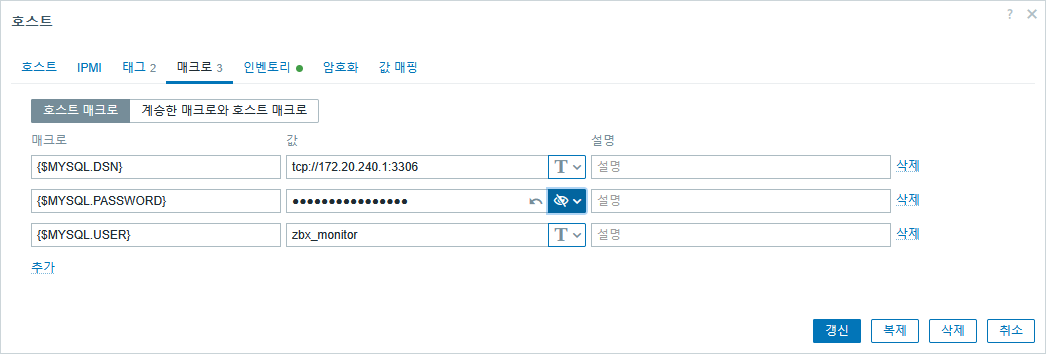
Docker 으로 생성된 DB 일경우 아래와 같이 {$MYSQL.DSN} 부분을 tcp://[ContainerIP]:3306으로 지정 해야 한다.
4. postgres
마찬가지로 감시 대상 DB에 zbx_monitor 용 어카운트를 생성해야 한다.
|
|
~]# psql -u Dba-ID -p -h localhost postgres password: 루트패스워드 |
|
|
postgres=> CREATE USER zbx_monitor WITH PASSWORD '비밀번호' INHERIT; postgres=> GRANT pg_monitor TO zbx_monitor; |
pg_hba.conf 파일에 하단에 아래 내용을 추가 한다. (경로: /etc/postgresql/[버전]/main/pg_hba.conf)
|
|
### for zabbix agent 2 host all zbx_monitor localhost trust host all zbx_monitor 127.0.0.1/32 md5 host all zbx_monitor ::1/128 scram-sha-256 |
설정한 이후 postgra 서비스를 재시작 해야 한다.
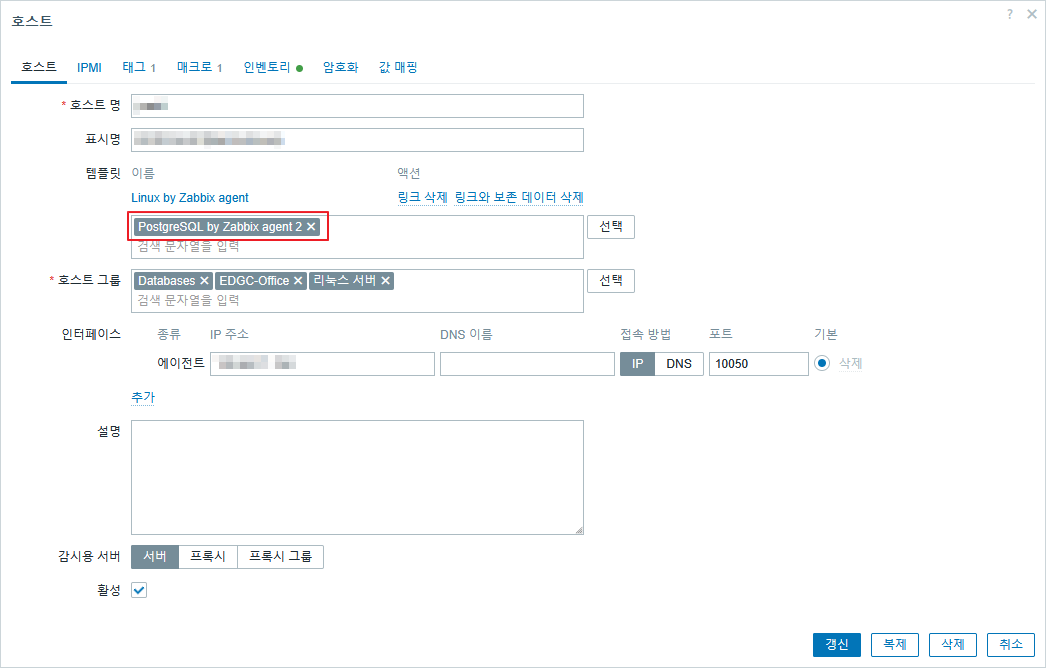
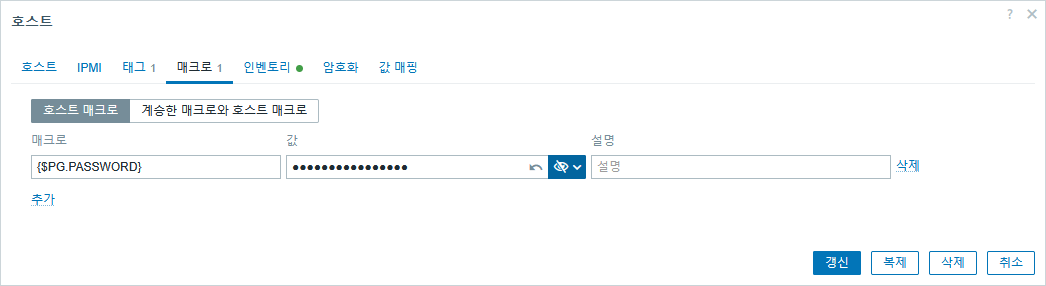
이후 웹UI 에서의 설정은 다음과 같이 PostgreSQL by Zabbix agent 2를 템플릿에 선언하고 매크로에 {$PG.PASSWORD}를 설정하면 된다.