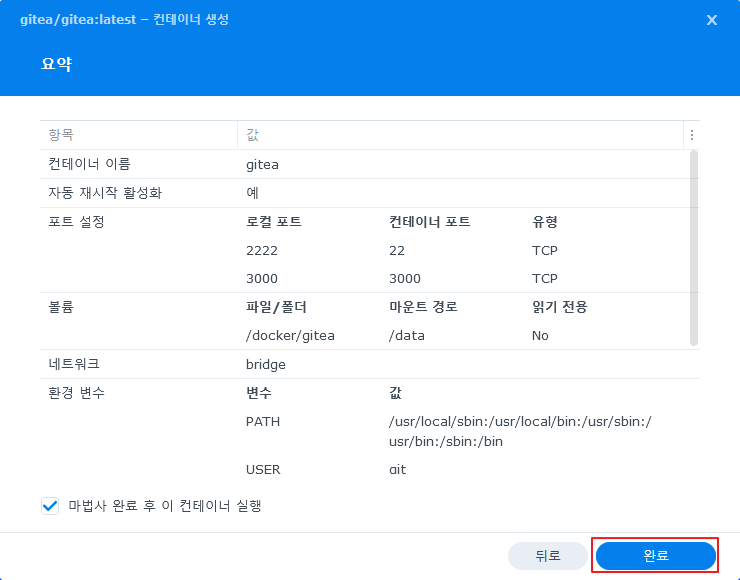
Synology에 M.2 Nvme 드라이브를 추가 해서 운영 하고 있다.
n100 미니PC 에서 적출해서 Synology에 추가해서 SSH 접속해서 lvm 명령어로 수동으로 파티션을 생성 해서 사용 했었다. (스크레치 디스크)
그런데 주기적으로 DSM이 업데이트가 되고 리부팅이 되면 구성해둔 볼륨을 인식 못하는 문제가 발생하였다.
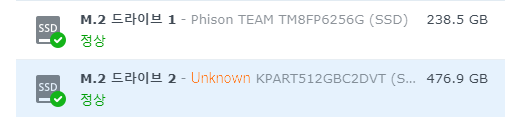
아울러서 Unknown으로 나오고 주의로 표시되는 부분도 그렇고…(위 스크린샷은 합성이다 -3-a)
1. Synology에 장착된 DISK 정보를 읽어서 데이터베이스를 생성 해주는 스크립트
https://github.com/007revad/Synology_HDD_db
2. 저장소 관리자(GUI) 에서 스토리지 풀 및 볼륨을 구성하는 스크립트
https://github.com/007revad/Synology_enable_M2_volume
두 스크립트의 제작자가 같아 사용법이 거의 같다.
그래서 두개의 스크립트를 같이 진행하지만 본인의 상황에 따라 스크립트 줄이거나 실행 옵션을 바꾸어 적용한다.
먼저 위 스크립트는 bash shell 코드로 작성되어 있으며 DSM 6, DSM 7을 지원 하는 것으로 밝히고 있다.
예시는 집에서 쓰고 있는 DS420+ 이다.
CPU: J4025 (2.0Ghz) 2C 2T
MEM: 2GB + 1 slot(16GB) = 18GB
HDD: HGST Deskstar 10TB * 4EA (MODE 5)
M.2: TEAM TM8FP6256G, KPART512GBC2DVT
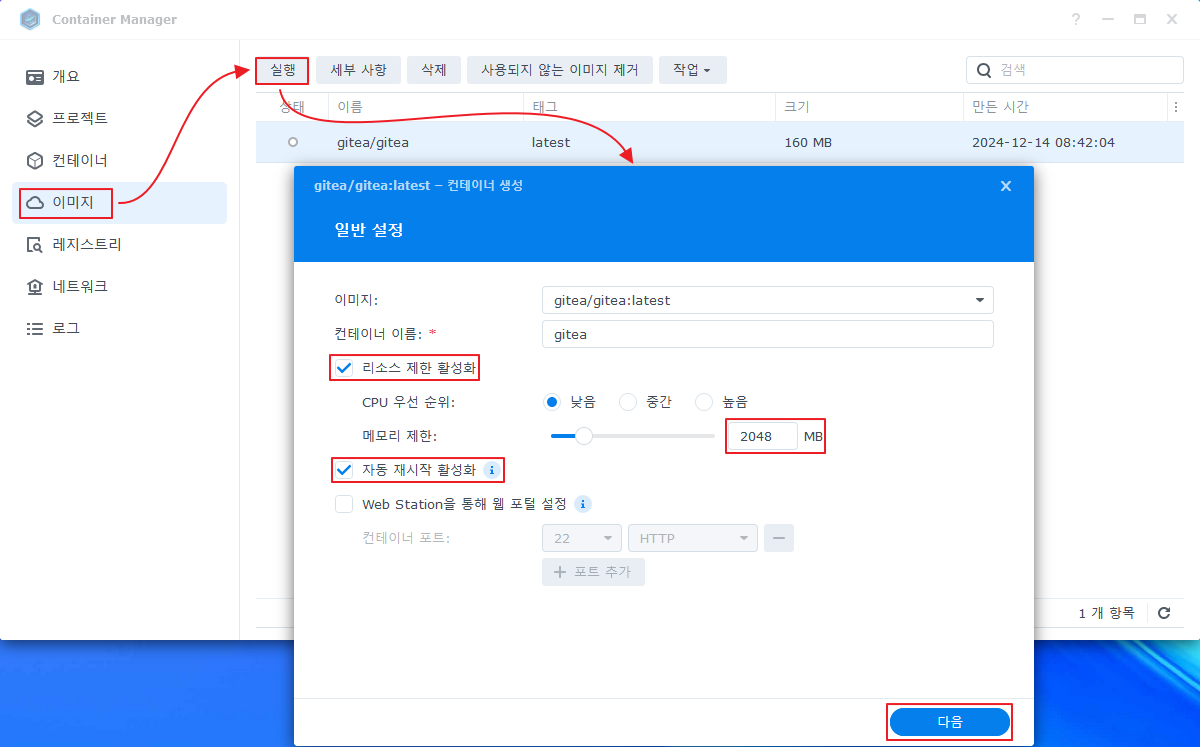
1. 첫번째 디스크 풀에 공유폴더 _SCRIPT 를 생성 한다.
주의: 스크립트는 M.2를 인식 시키기 위한 것이기 때문에 M.2 에 공유폴더를 생성 하면 안된다.
2. github 사이트에서 최신 릴리즈의 배포 파일을 다운 받는다.
https://github.com/007revad/Synology_HDD_db/releases
https://github.com/007revad/Synology_enable_M2_volume/releases
3. _SCRIPT 폴더에 배포 파일을 넣고 모두 압축을 해제 한다.
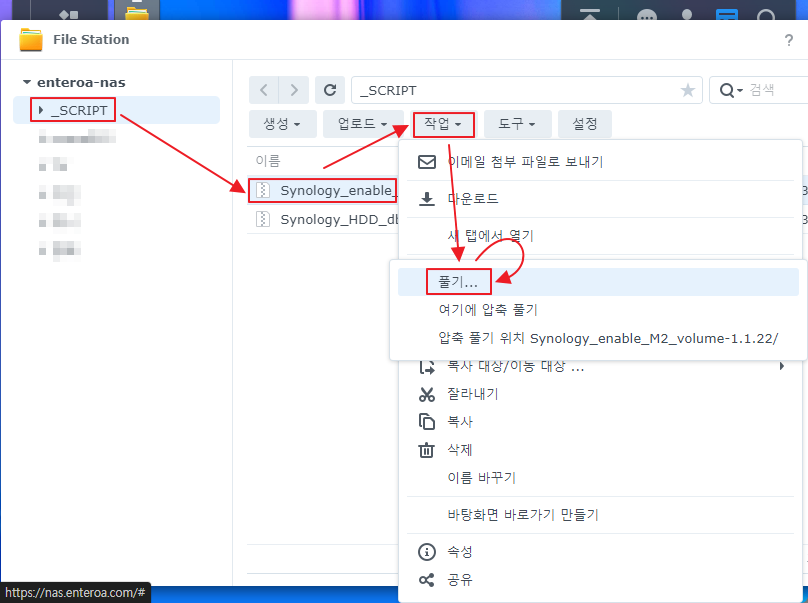
M.2(KPART512GBC2DVT) – (알리발 N100 랩탑에서 적출함) 의 경우 Unknown으로 표시 되기 때문에 Synology 에 ssh 서비스를 활성화 하고 ssh 접속 후 스크립트를 실행해서 아래와 같은 메세지를 확인했다.
|
|
:~$ sudo -i :~# bash /volume1/_SCRIPT/Synology_HDD_db-3.5.103/syno_hdd_db.sh WARNING No Vendor Found for vid 0xefff You can add 0xefff add your drive's vendor to: /volume1/_SCRIPT/Synology_HDD_db-3.5.103/syno_hdd_vendor_ids.txt |
KPART512GBC2DVT는 구글 검색을 했을때 HUADISK으로 확인 되어 /volume1/_SCRIPT/Synology_HDD_db-3.5.103/syno_hdd_vendor_ids.txt 파일 하단에 0xefff="HUADISK" 추가 했다.
이후 스크립트를 실행하면 /usr/syno/etc.defaults/pci_vendor_ids.conf 에 코드에 맞는 벤더를 선언해서 Unknown을 지정한 벤더로 나오게 된다.
4. 나스 재시작시(자동 업데이트 후) 자동 적용을 위한 스케쥴러에 등록 한다.
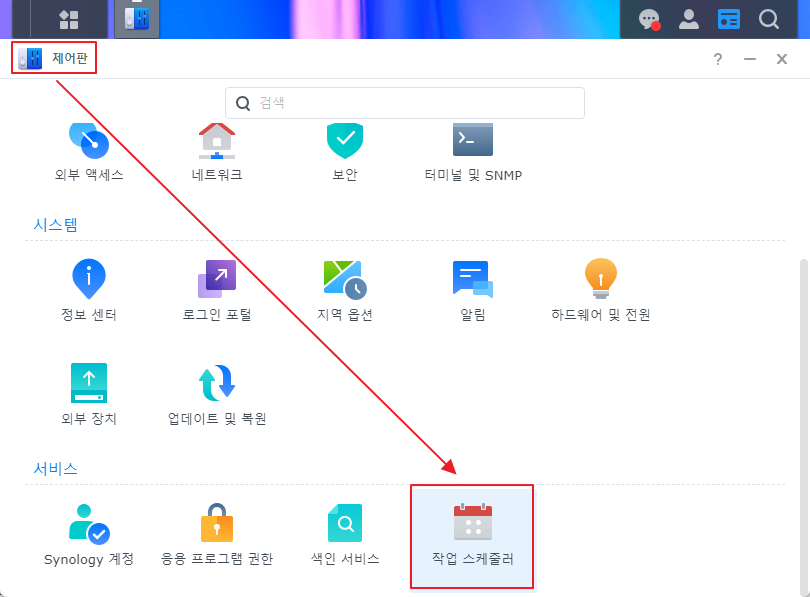
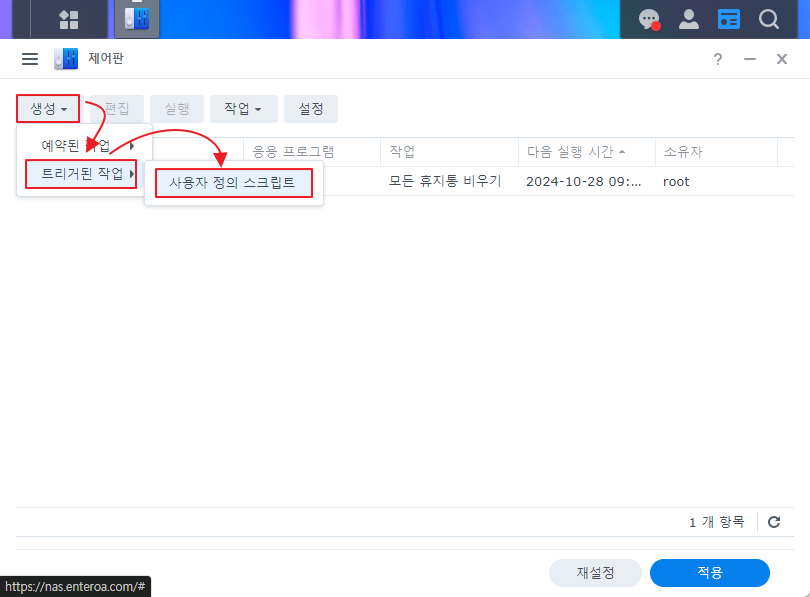
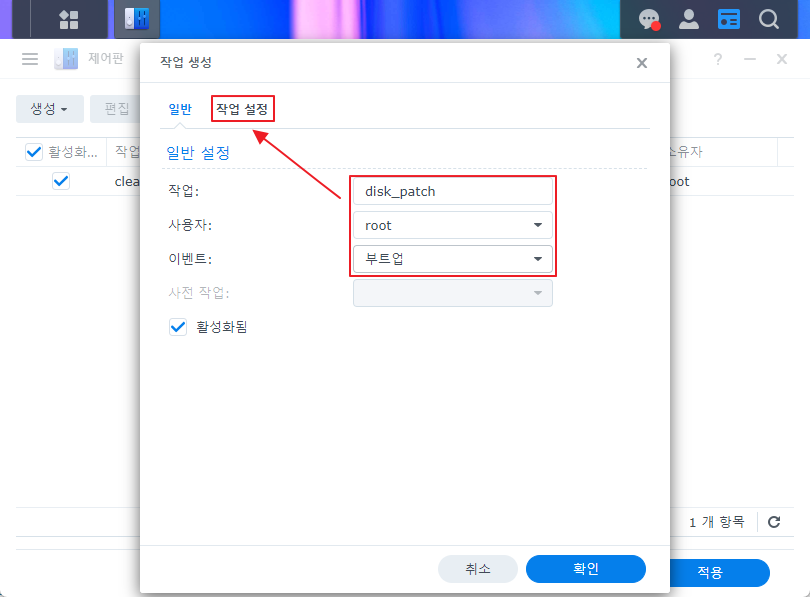
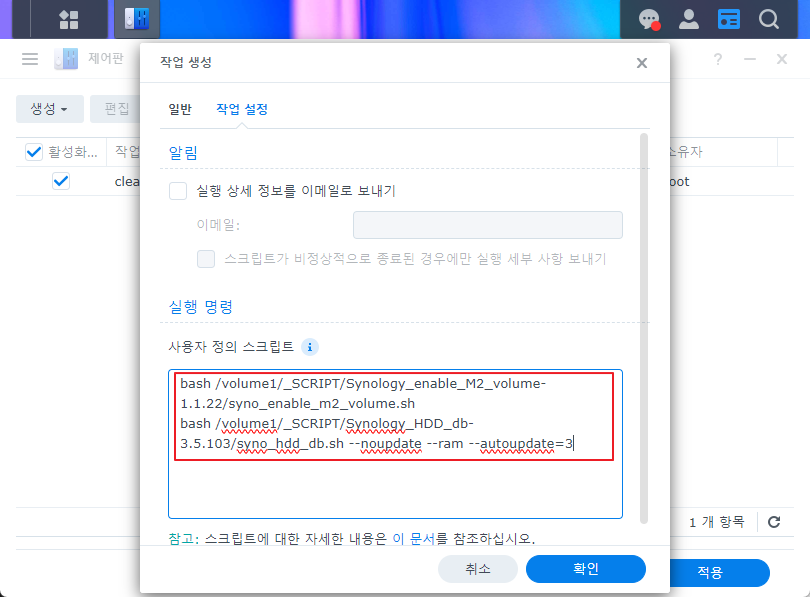
|
|
bash /volume1/_SCRIPT/Synology_enable_M2_volume-1.1.22/syno_enable_m2_volume.sh bash /volume1/_SCRIPT/Synology_HDD_db-3.5.103/syno_hdd_db.sh --noupdate --ram --autoupdate=3 |
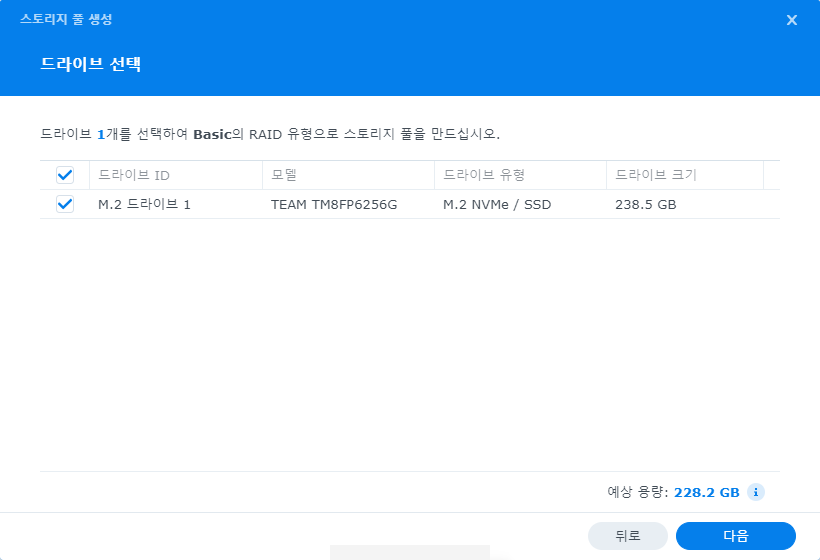
syno_enable_m2_volume.sh는 별다른 옵션 없이 실행 하면 “저장소 관리자(GUI)” 에서 M.2 스토리지 풀 생성이 가능하다.
syno_hdd_db.sh은 /var/lib/disk-compatibility/ds420+_host_v7.db 파일을 ds420+_host_v7.db.bak 파일로 백업 하고 로컬에서 검색된 디스크 정보를 추가하여 ds420+_host_v7.db 파일을 생성 해주는 기능이 들어 있다.
syno_hdd_db.sh 의 추가된 스크립트 옵션은 다음과 같다.
--noupdate synology 의 hdd DB 업데이트 기능을 끈다.(이로 인해 synology 내부 메세지가 발생할 수 있다.)
--ram 내 가정용 DS420+는 최대 크기(8GB)를 넘어 18GB으로 사용하고 있기 때문에 필요한 옵션이다.
--autoupdate=3 이 스크립트는 자동 업데이트 기능이 있는데 새 버전이 나오면 3일 이후 업데이트를 한다.
내가 쓰지는 않았지만 유용한 옵션
--incompatible 12bay 이상에서 Synology HDD 사용을 하지 않을 경우 주의로 나오것을 방지 한다.
--pcie Synology 외의 PCI-E NVME 확장 카드를 사용 가능하도록 한다.
--wdda W/D 하드의 경우 사용 기간이 3년 넘어갈 경우 warning 이 표시되는것을 방지 한다.
--ssd=sata1 주 하드디스크(primary reads)를 선언할 수 있다. (sata1 | sata1,sata2 | sda 처럼 지정 하거나 기본값 restore 으로 설정 가능)
설정이 완료 되면 Synology NAS를 재시작 하고 웹으로 접속(DSM) 저장소 관리자 에서 M.2 디스크로 볼륨을 생성할 수 있다